This article focuses on various ways to visualize personal light
exposure data with LightLogR. It is important to note that
LightLogR is using the ggplot2 package for
visualizations. This means that all the ggplot2 functions
can be used to further customize the plots. The following packages are
needed for the analysis:
Please note that this article uses the base pipe operator
|>. You need an R version equal to or greater than 4.1.0 to use it. If you are using an older version, you can replace it with themagrittrpipe operator%>%.
Importing Data
We will use data imported and cleaned already in the article Import & Cleaning.
#this assumes the data is in the cleaned_data folder in the working directory
data <- readRDS("cleaned_data/ll_data.rds")gg_overview()
gg_overview() provides a glance at when data is
available for each Id. Let’s call it on our dataset.
data |> gg_overview()
As can be seen the dataset contains 17 ids with one weeks worth of
data each, and one to three participants per week.
gg_overview() will by default test whether there are gaps
in the data and will show them as grey bars, as well as a message in the
lower right corner. Let us force this behavior in our dataset by
removing two days.
data |>
filter(
!(date(Datetime) %in% c("2023-08-16", "2023-08-17"))
) |>
gg_overview()
Calculating gaps in the data can be computationally expensive for
large datasets with small epochs. If you just require an overview of the
data without being concerned about gaps, you can provide an empty
tibble::tibble() to the gap.data argument.
This will skip the gap calculation and speed up the graph
generation.
data |>
filter(
!(date(Datetime) %in% c("2023-08-16", "2023-08-17"))
) |>
gg_overview(gap.data = tibble())
Hint: gg_overview() is automatically called by
import functions in LightLogR, unless the argument
auto.plot = FALSE is set. If your import is slow, this can
also help in speeding up the process.
gg_day()
Basics
gg_day() compares days within a dataset. By default it
will use the date. Let’s call it on a subset of our data.
To distinguish between different Ids, we can set the
aes_col argument to Id.
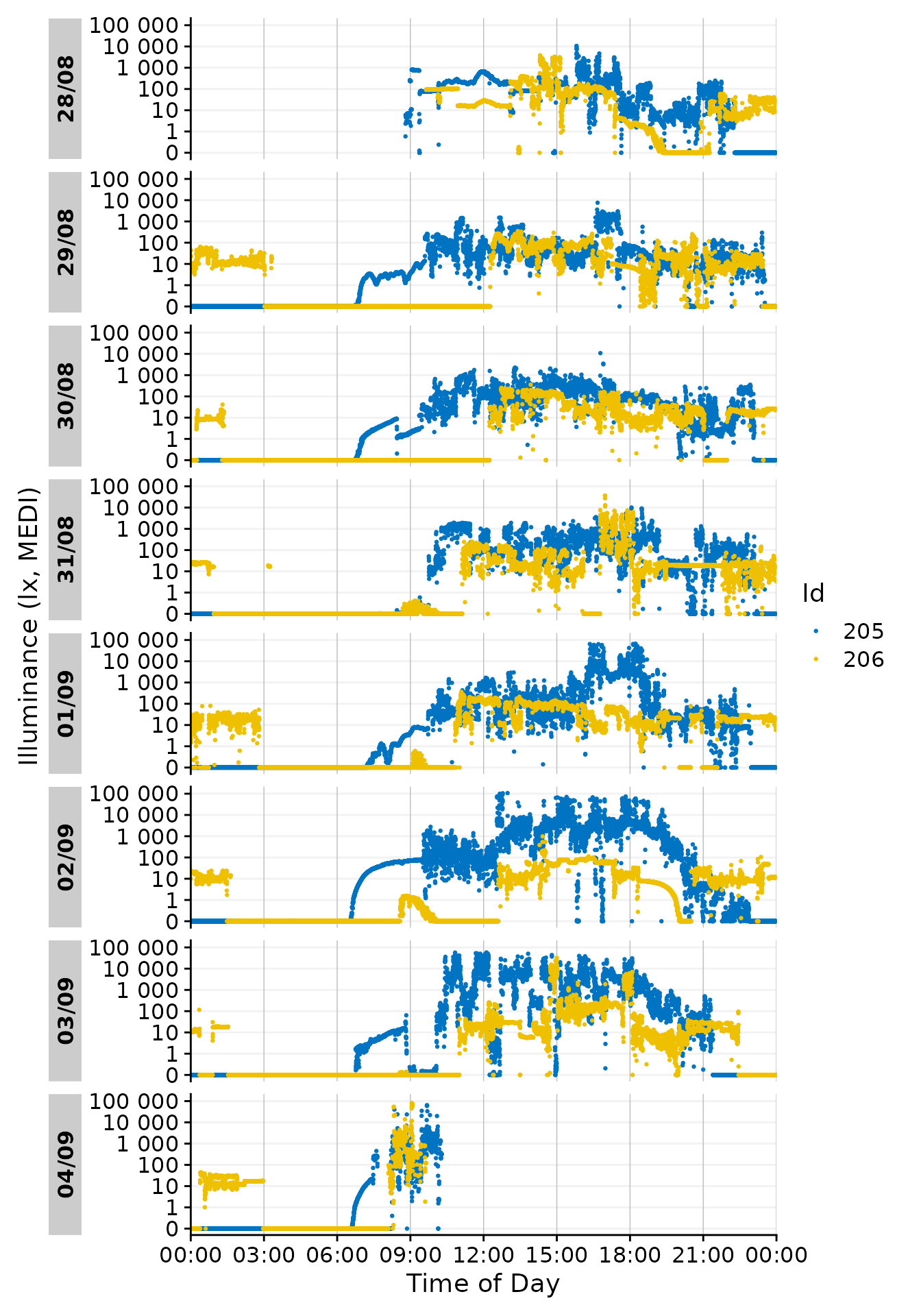
Facetting
Note that each day is represented by its own facet, which is named
after the date. We can give each Id its own facet by using the
ggplot2::facet_wrap() function. The Day.data
column is produced by gg_day() and contains the structure
of the daily facets. It has to be used by facet_wrap() to
ensure that the facets are shown correctly. We also reduce the breaks on
the x-axis to avoid overlap at 00:00.
data |>
filter(Id %in% c(205, 206)) |>
gg_day(aes_col = Id, size = 0.5,
x.axis.breaks = hms::hms(hours = c(0, 6, 12, 18))) +
guides(color = "none") +
facet_grid(rows = vars(Day.data), cols = vars(Id), switch = "y")
Date-grouping
Showing the days by date is the default behavior of
gg_day(). It can also be grouped by any other formatting of
base::strptime(). Using format.day = "%A" in
the function call will group all output by the weekday. Putting so many
Participants in each facet makes the plot unreadable, but it
demonstrates how gg_day() can be configured to combine
observations from different dates. We have to provide a different color
scale compared to the default one, as the default has only 10 colors
compared to the 17 we need here.
data |>
gg_day(aes_col = Id, size = 0.5, format.day = "%A") +
scale_color_viridis_d()
#> Scale for colour is already present.
#> Adding another scale for colour, which will replace the existing scale.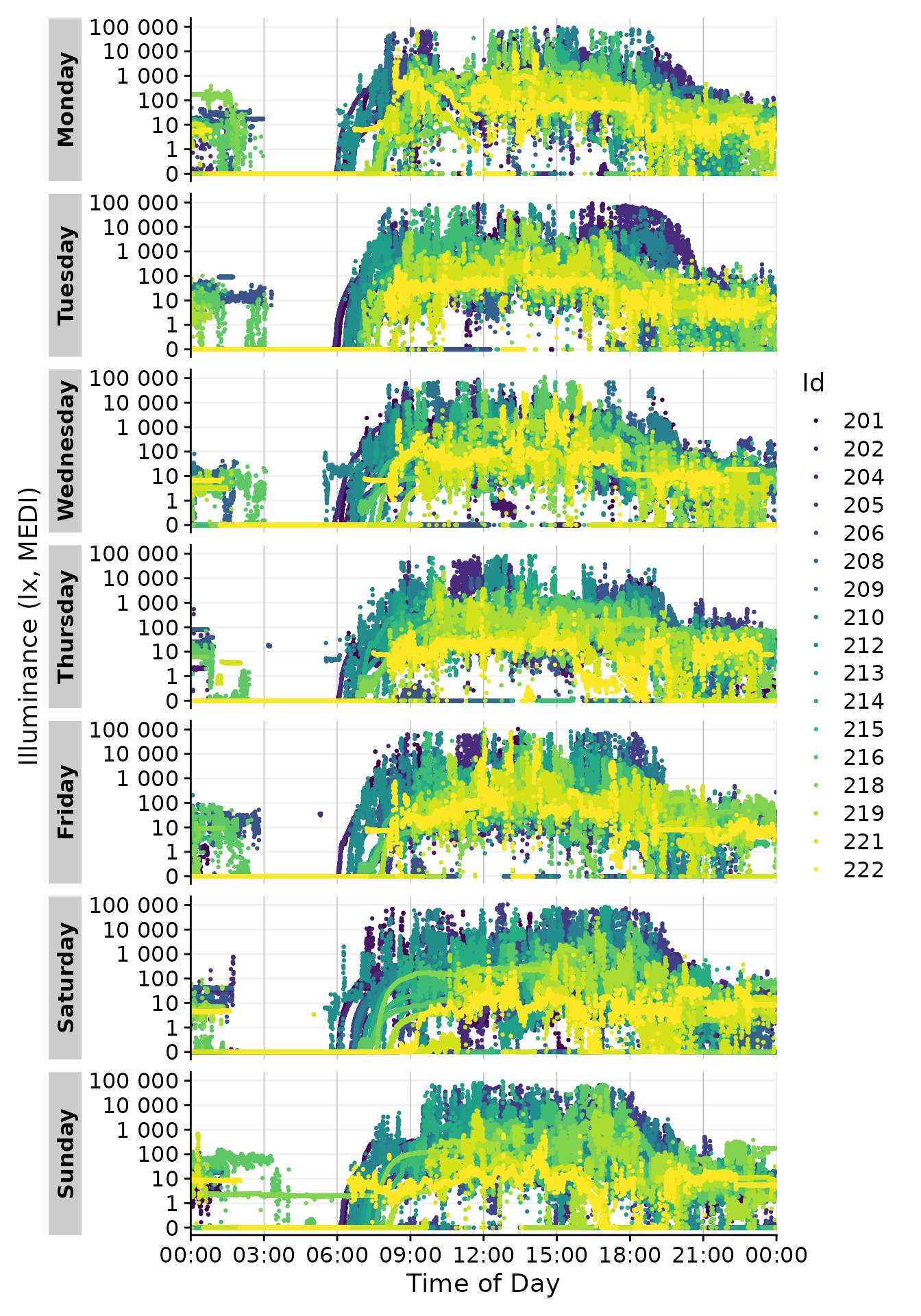
Customizing geoms and miscellanea
gg_day() uses geom_point() by default. This
can be changed by providing a different geom to the
function. Here we use geom_line() to connect the points. To
make this more readable. Let us first recreate a simpler version of the
above dataset by filtering and aggregating
data_subset <-
data |>
filter(Id %in% c(205, 206)) |> #choosing 2 ids
aggregate_Datetime(unit = "15 mins") |> #aggregating to 15 min intervals
filter_Datetime(length = "3 days", full.day = TRUE) #restricting their length to 3 days
data_subset |>
gg_day(aes_col = Id)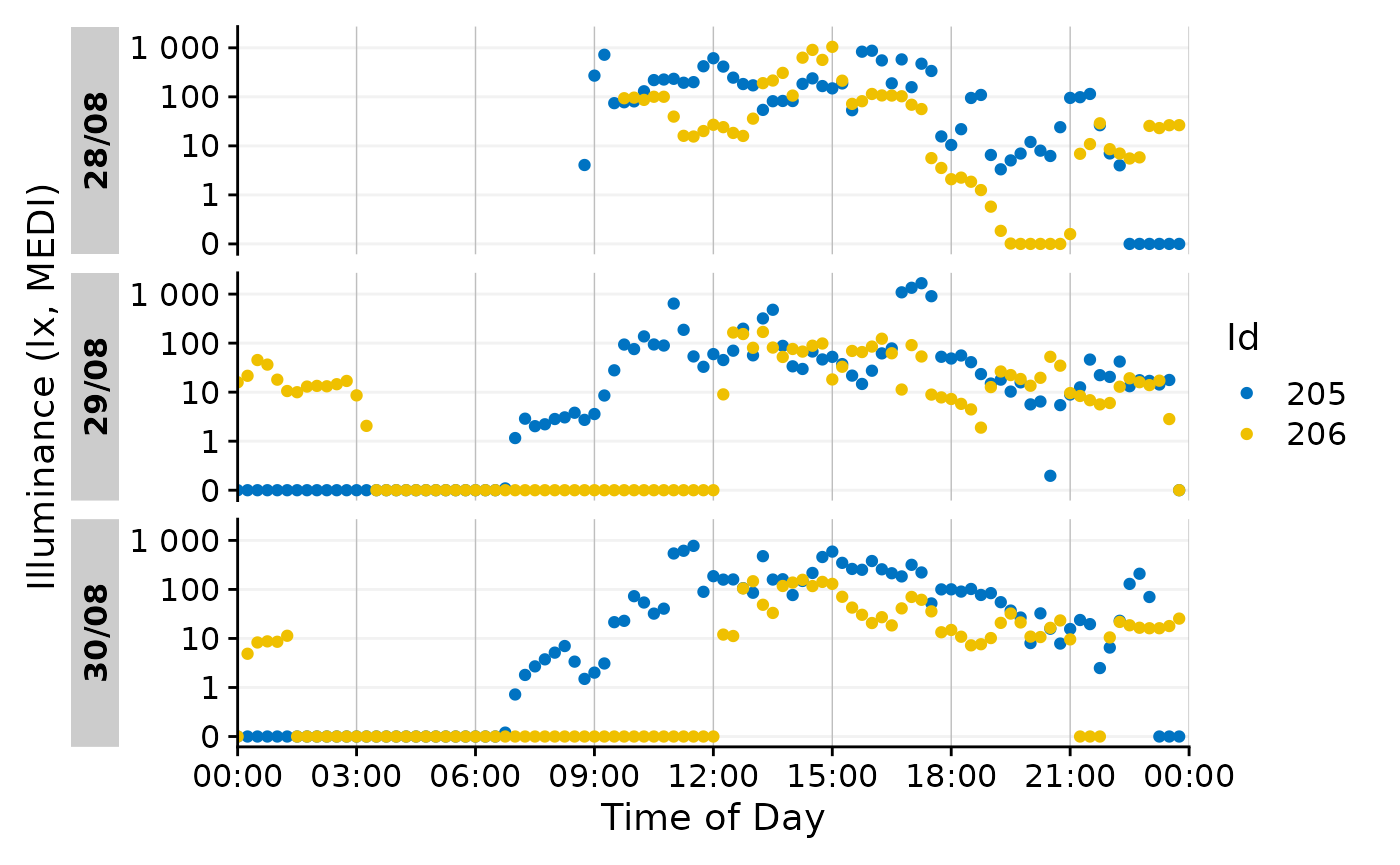
Now we can use a different geom.
data_subset |>
gg_day(aes_col = Id, geom = "line")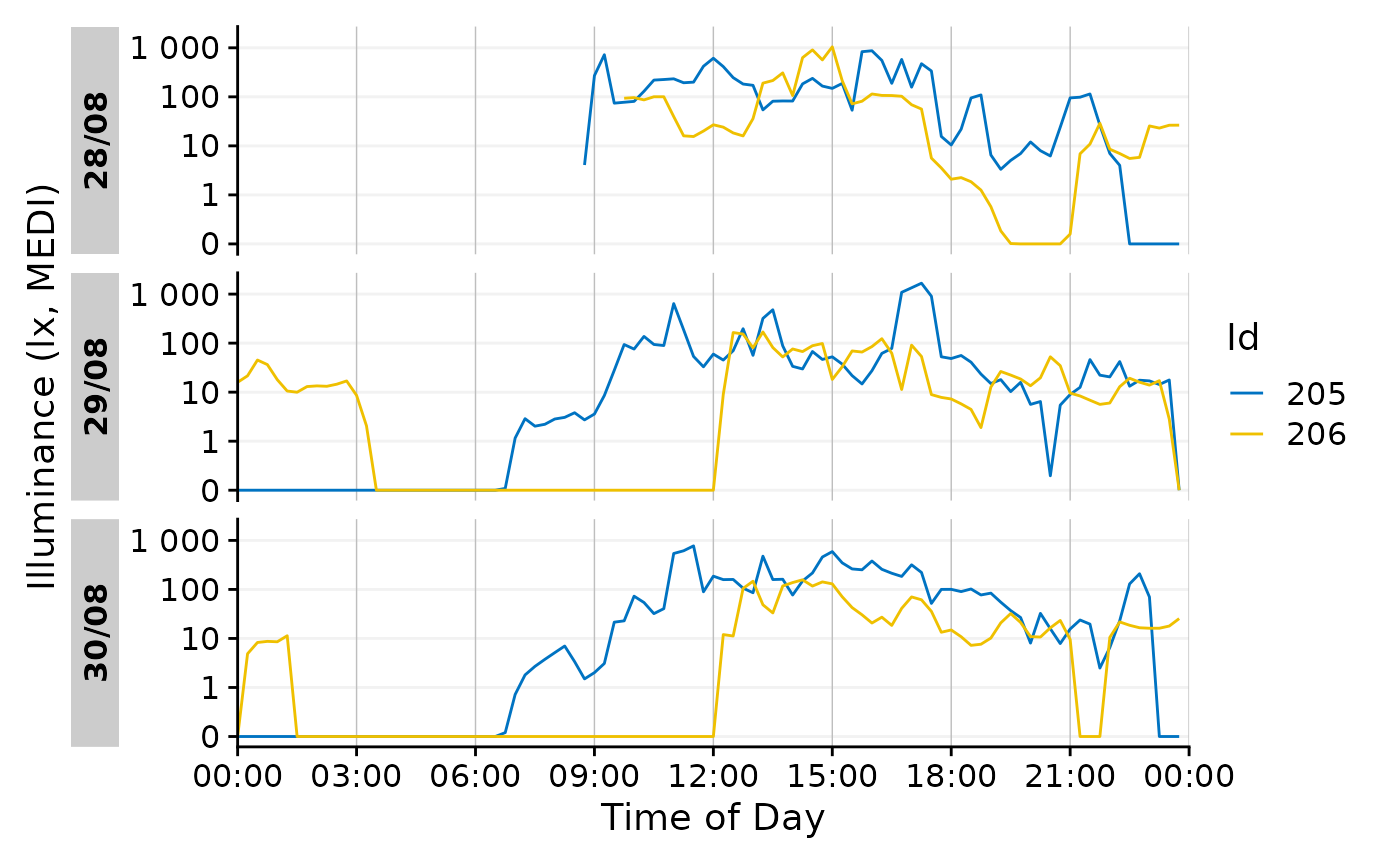
Also a ribbon is possible.
data_subset |>
gg_day(aes_col = Id, aes_fill = Id, geom = "ribbon", alpha = 0.5)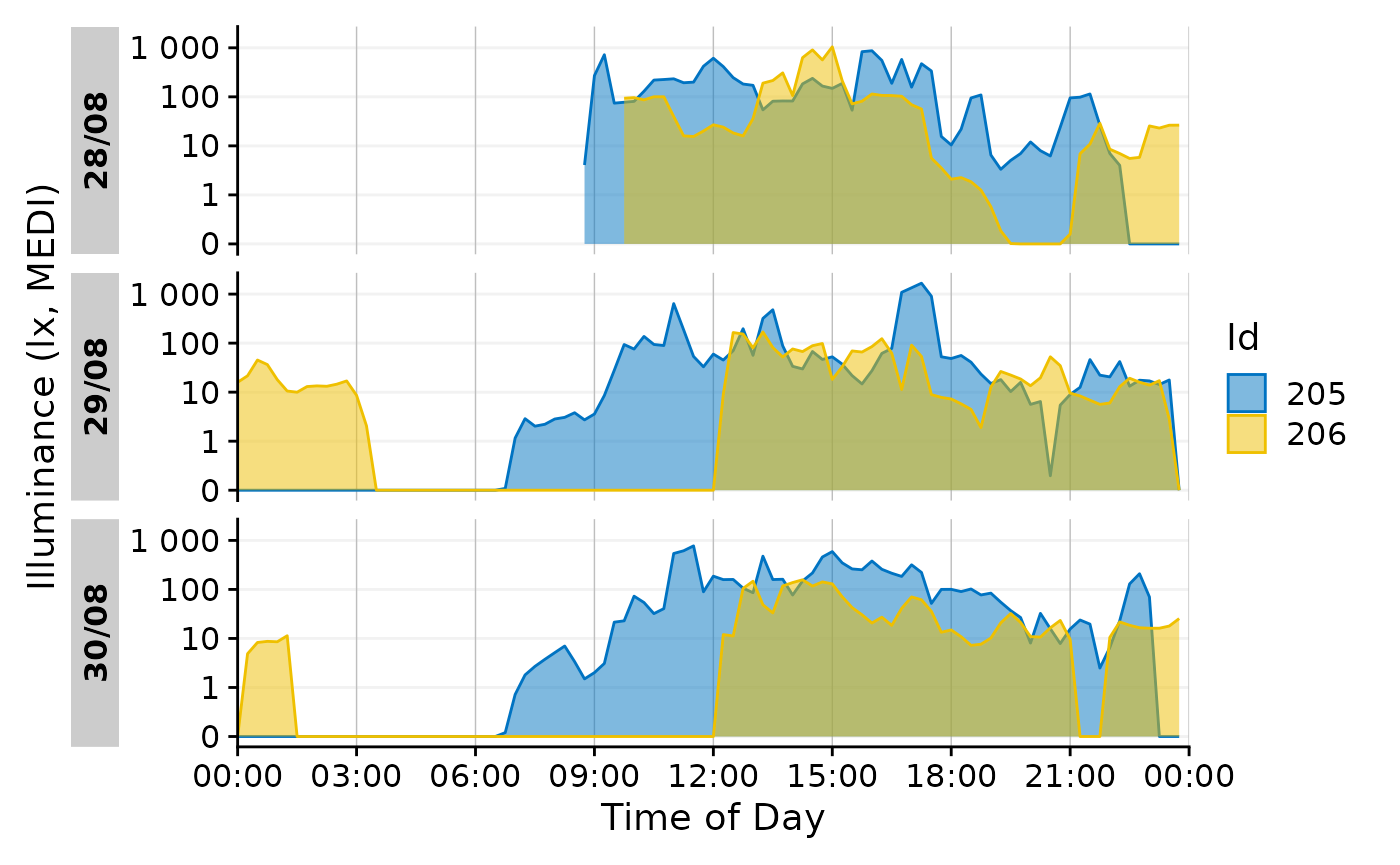
gg_days()
This is the companion function to gg_day(). Instead of
using individual days, it will create a timeline of days across all
Ids.
data_subset2 <-
data |>
filter(Id %in% c(205, 216, 219)) |> #choosing 3 ids
aggregate_Datetime(unit = "15 mins") #aggregating to 15 min intervals
data_subset2 |>
gg_days()
By default, gg_days() will always plot full days. Let us
strip one participant of data for three days.
data_subset3 <-
data_subset2 |>
filter(!(Id == 205 &
date(Datetime) %in% c("2023-08-29", "2023-08-30", "2023-08-31")))
data_subset3 |>
gg_days()
You can see the plots are misaligned in their facets. We can correct
for that by providing an exact number of days to the
x.axis.limits argument. Datetime_limits() is a
helper function from LightLogR and the documentation
reveals more about its arguments.
data_subset3 |>
gg_days(
x.axis.limits =
\(x) Datetime_limits(x, length = ddays(5), midnight.rollover = TRUE)
)
gg_days() has all of the customization options of
gg_day(). Here we will customize the plot for a ribbon,
different naming and breaks on the datetime axis.
data_subset3 |>
gg_days(
geom = "ribbon", aes_col = Id, aes_fill = Id, alpha = 0.5, jco_color = TRUE,
x.axis.limits =
\(x) Datetime_limits(x, length = ddays(5), midnight.rollover = TRUE),
x.axis.breaks =
\(x) Datetime_breaks(x, by = "6 hours", shift = 0),
x.axis.format = "%H",
) +
guides(color = "none", fill = "none")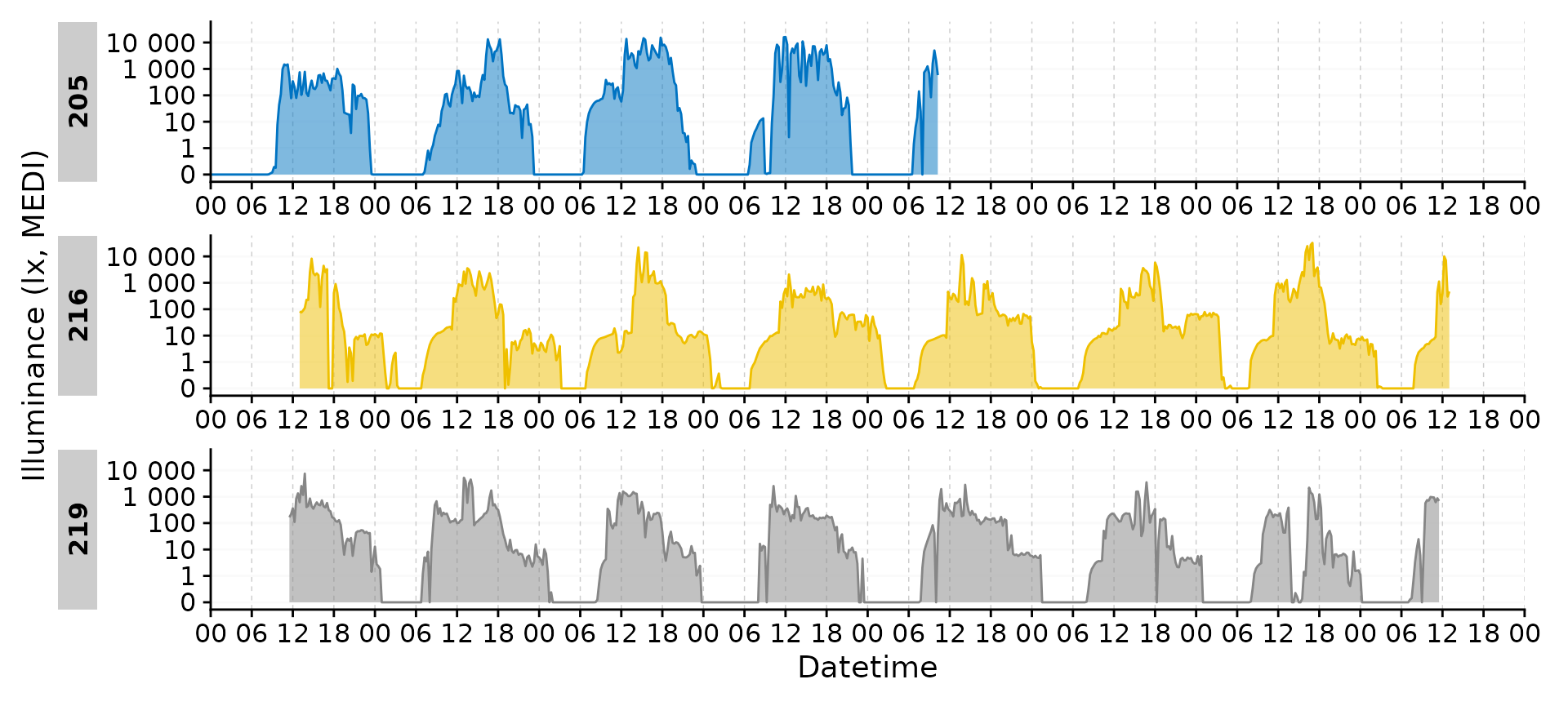
gg_heatmap()
gg_heatmap() is a simple but handy feature to get an
overview over large time periods across groups. (For some unknown
reason, it tends to produce a warning about uneven horizontal intervals,
which can be safely ignored)
data |> gg_heatmap()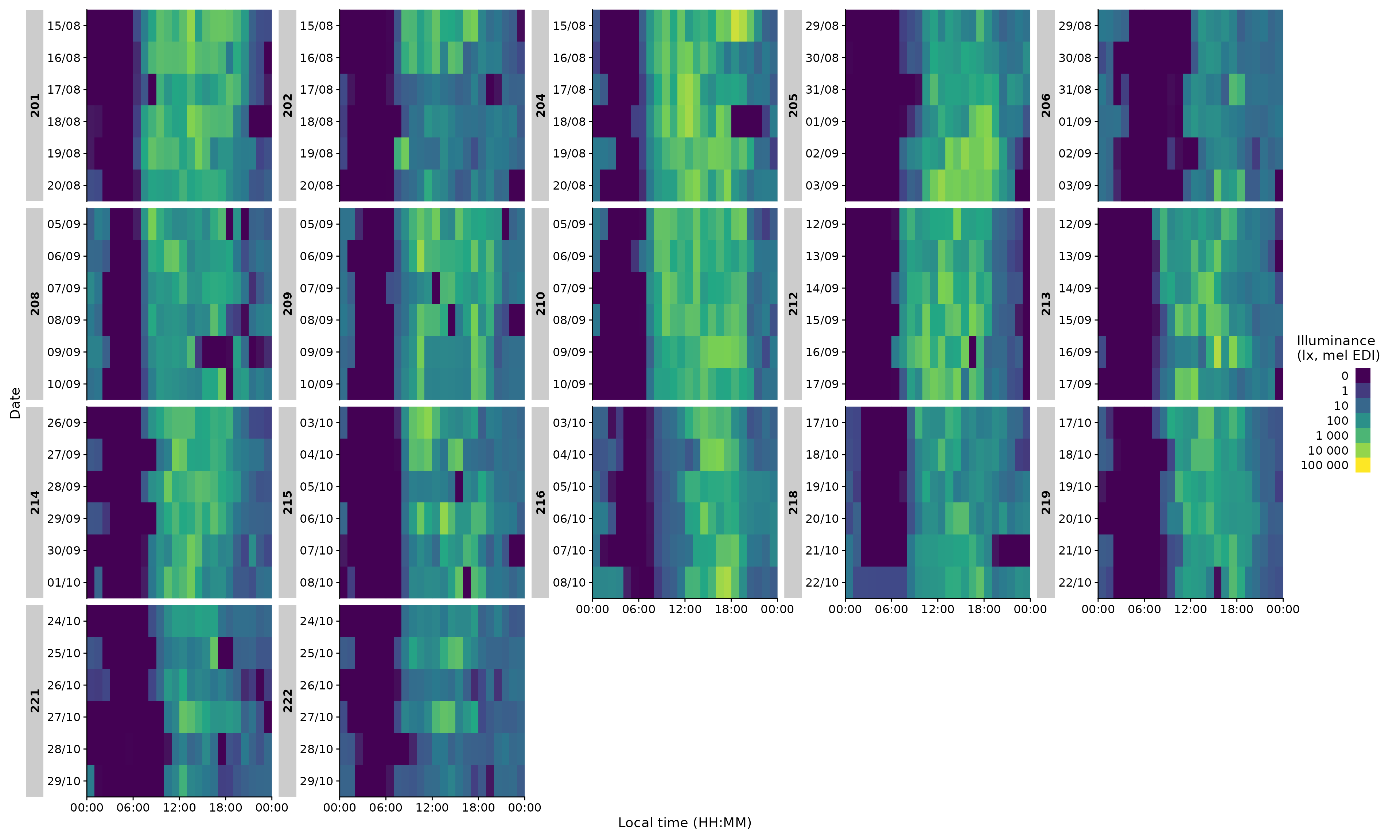
The function does not have a ton of individualization, but there are some options:
data |>
filter(Id %in% c(204, 216, 218)) |> #choosing 3 ids
gg_heatmap(fill.limits = c(0,NA)) #sets the upper limit to the max value#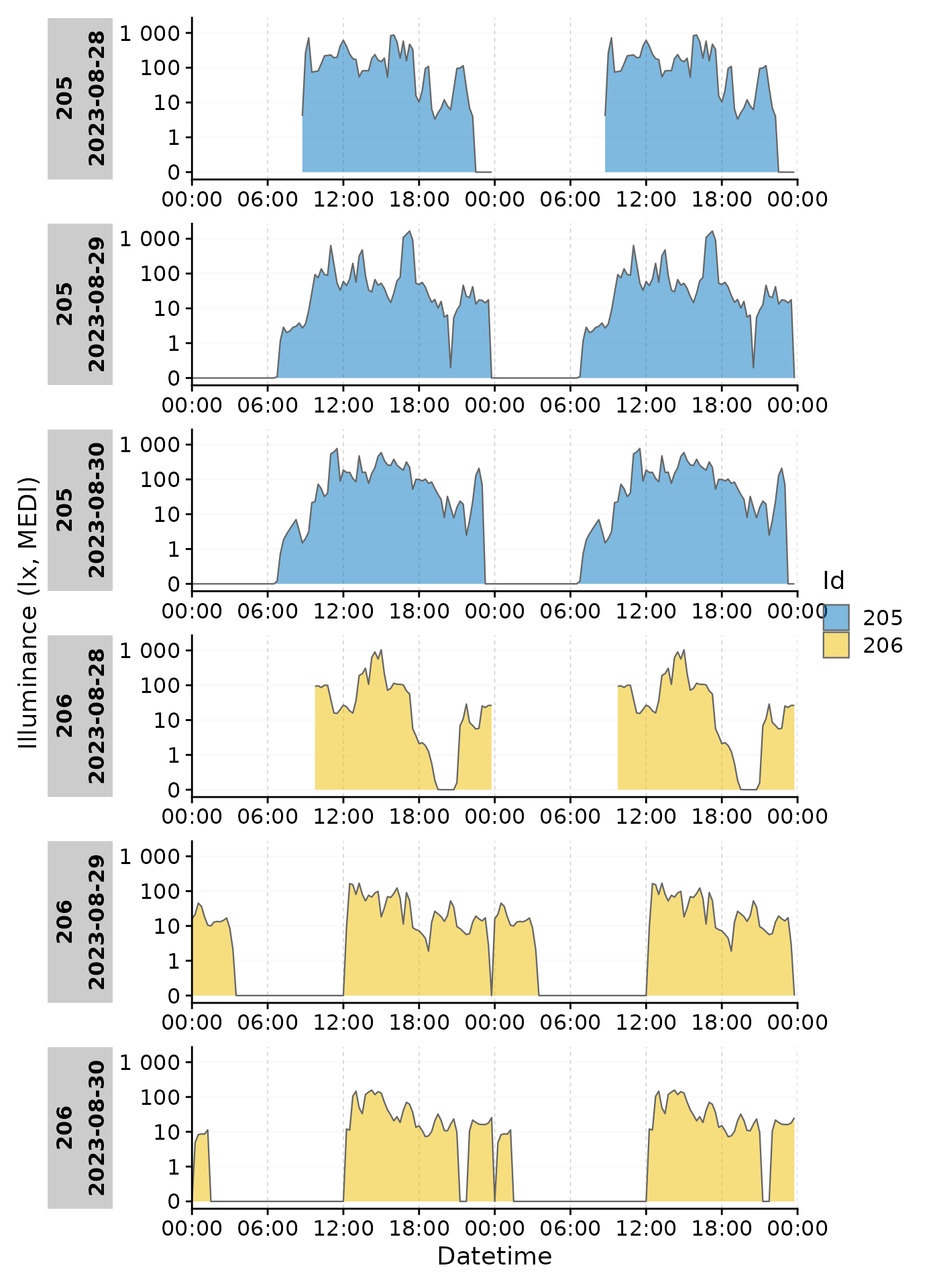
data |>
filter(Id %in% c(204, 216, 218)) |> #choosing 3 ids
gg_heatmap(unit = "5 mins") #changes the binning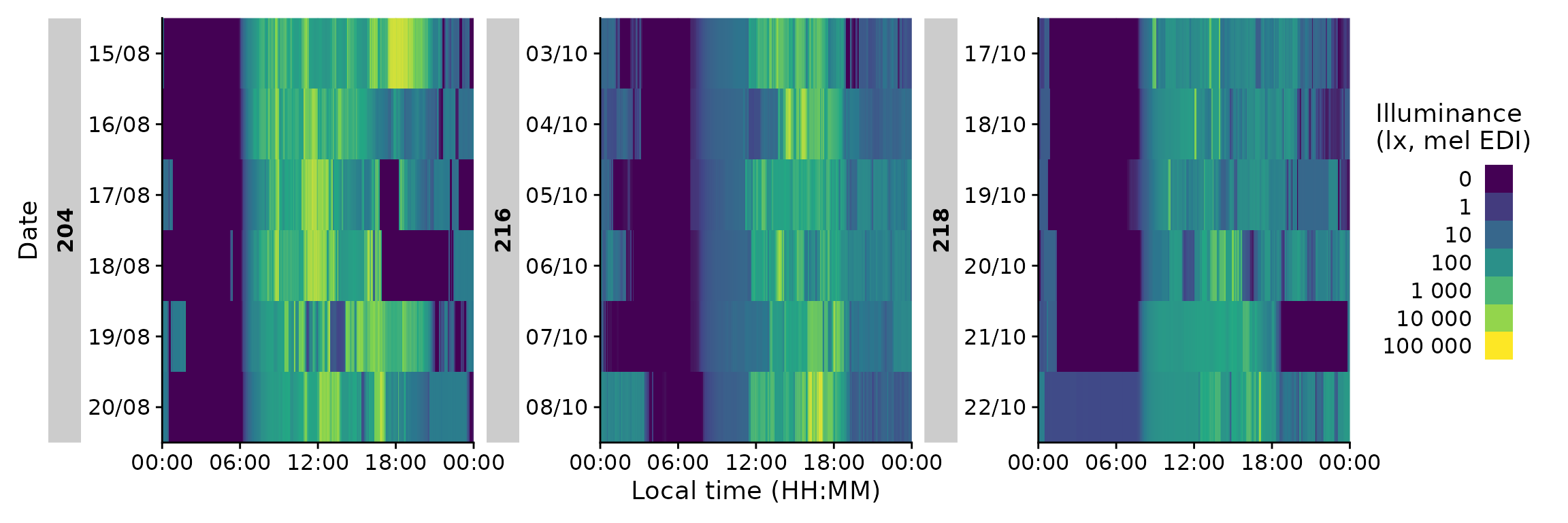
Importantly, it has a handy doubleplot feature, either showing the
next, or the same day repeated
data |>
filter(Id %in% c(204, 216, 218))|>
gg_heatmap(doubleplot = "next", fill.limits = c(0, NA))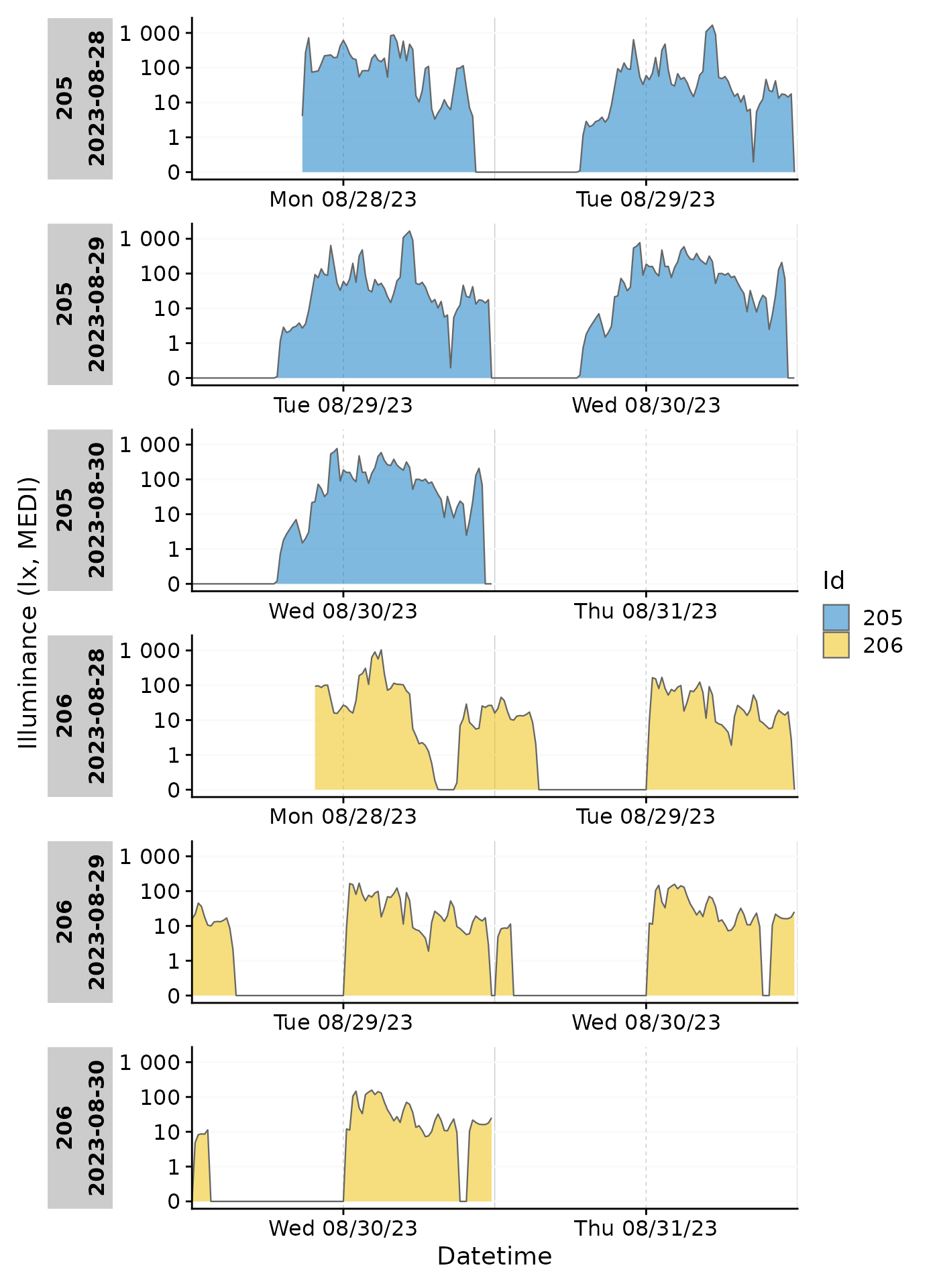
Finally, we can use heatmaps to produce an Actigram-like plot.
data |>
filter(Id %in% c(204, 216, 218))|>
gg_heatmap(Variable.colname = MEDI >= 50,
doubleplot = "next",
fill.limits = c(0, NA),
fill.remove = TRUE, fill.title = ">50lx MEDI") +
scale_fill_manual(values = c("TRUE" = "black", "FALSE" = "#00000000"))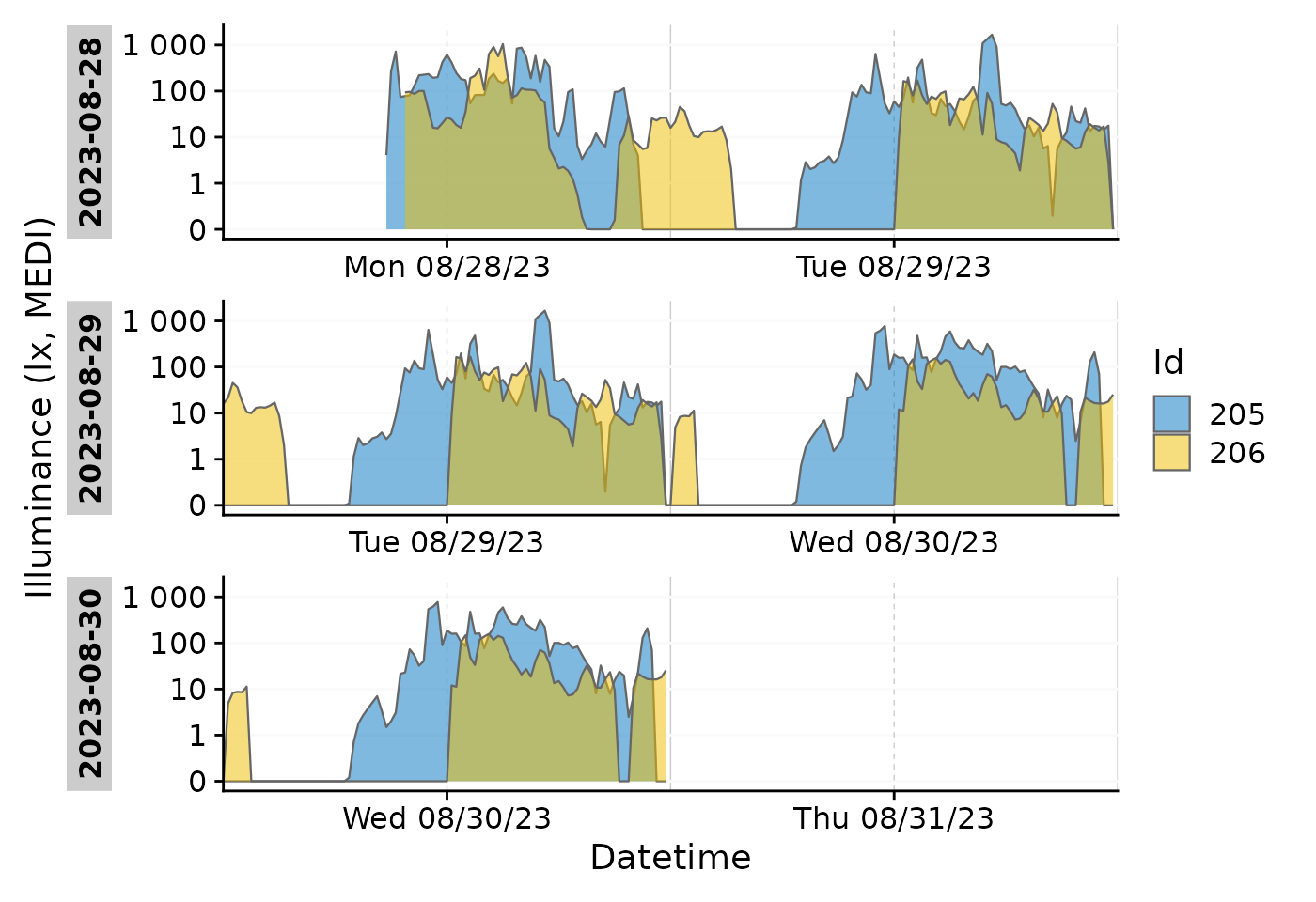
gg_doubleplot()
A more generalized implementation of doubleplots is realized with
gg_doubleplot(): it repeats days within a plot, either
horizontally or vertically. Doubleplots are generally useful to
visualize patterns that center around midnight (horizontally) or that
deviate from 24-hour rhythms (vertically).
Preparation
We will use a subset from the data used in gg_day()
above: two Ids, aggregated to 15-minute intervals, and restricted to
three days. Because the first day is only partly present for both Ids,
we will use the gap_handler() function to fill in the
implicitly missing data with NA. If we ignore this step, the doubleplot
will be incorrect, as it will connect the last point of the first day
(around midnight) with the first point of the second day (somewhen
before noon), which is incorrect and also looks bad.
data_subset <-
data_subset |>
gap_handler(full.days = TRUE)Horizontal doubleplot
The horizontal doubleplot is activated by default, if only one day is
present within all provided groups, or it can be set explicitly by
type = "repeat".
data_subset |>
gg_doubleplot(aes_fill = Id, jco_color = TRUE, type = "repeat")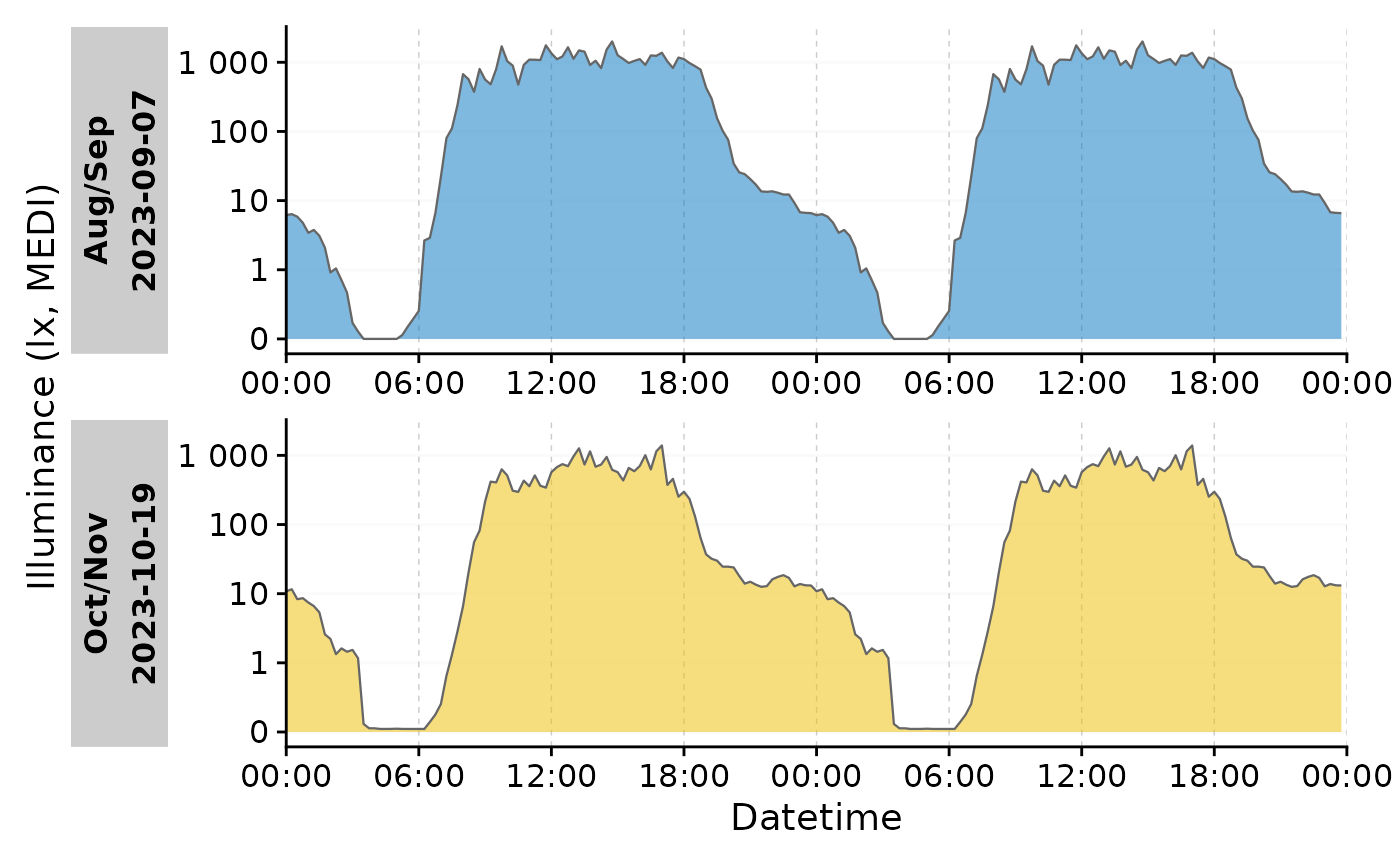
#identical:
# data_subset |>
# group_by(Date = date(Datetime), .add = TRUE) |>
# gg_doubleplot(aes_fill = Id, jco_color = TRUE)Each plot line thus is the same day, plotted twice.
Vertical doubleplot
The vertical doubleplot is activated by default if any group has more
than one day. It can be set explicitly by
type = "next".
data_subset |>
gg_doubleplot(aes_fill = Id, jco_color = TRUE)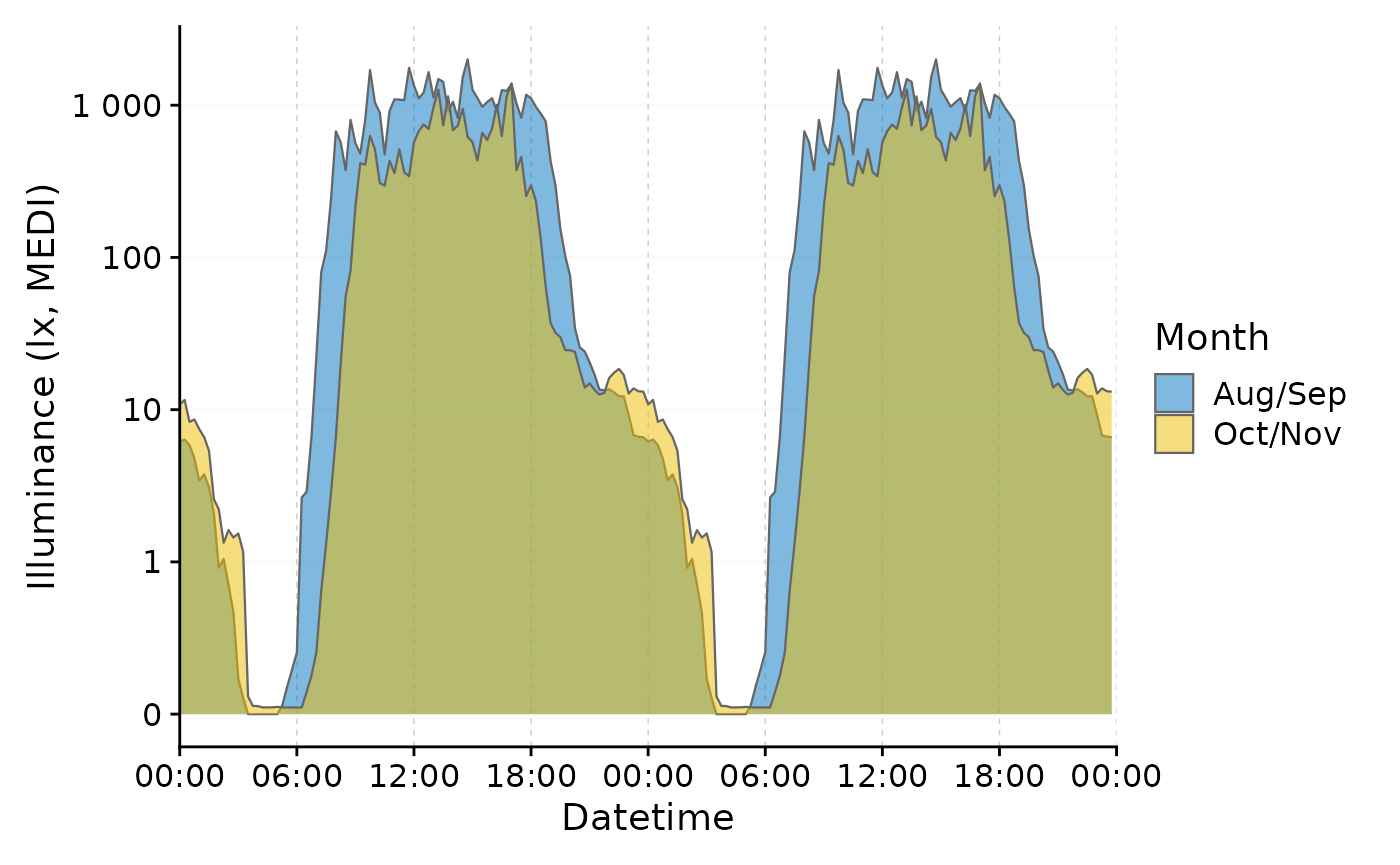
#identical:
# data_subset |>
# gg_doubleplot(aes_fill = Id, jco_color = TRUE, type = "next")Note that the second day in each row is the first day of the next
row. This allows to visualize non-24-hour rhythms, such as when
Entrainment is lost due to pathologies or experimental conditions. Note
that the x-axis labels change automatically depending on whether the
doubleplot has type "next" or "repeat".
In both cases (horizontally and vertically) it is easy to condense the plots to a single line per day, by ungrouping the data structure (makes only sense if the datetimes are identical):
data_subset |>
ungroup() |>
gg_doubleplot(aes_fill = Id, jco_color = TRUE)
Aggregated doubleplot
Independent of gg_doubleplot(), but great in concert
with it is aggregate_Date(), which allows to aggregate
groups of data to a single day each. This way, one can easily calculate
the average day of a participant or a group of participants and then
perform a doubleplot (by default with type = "next").
Let us first group our data by whether participants were in the first or last two months of the experiment.
data_two_groups <- data |>
mutate(
Month = case_when(month(Datetime) %in% 8:9 ~ "Aug/Sep",
month(Datetime) %in% 10:11 ~ "Oct/Nov")
) |>
group_by(Month)Now we can aggregate the data to a single day per group and make a
doubleplot from it. With aggregate_Date() we condense a
large dataset with 10-second intervals to a single day for two groups
with a 15 minute interval. The day that is assigned by default is the
median measurement day of the group.
data_two_groups |>
aggregate_Date(unit = "15 mins") |>
gg_doubleplot(aes_fill = Month, jco_color = TRUE) +
guides(fill = "none")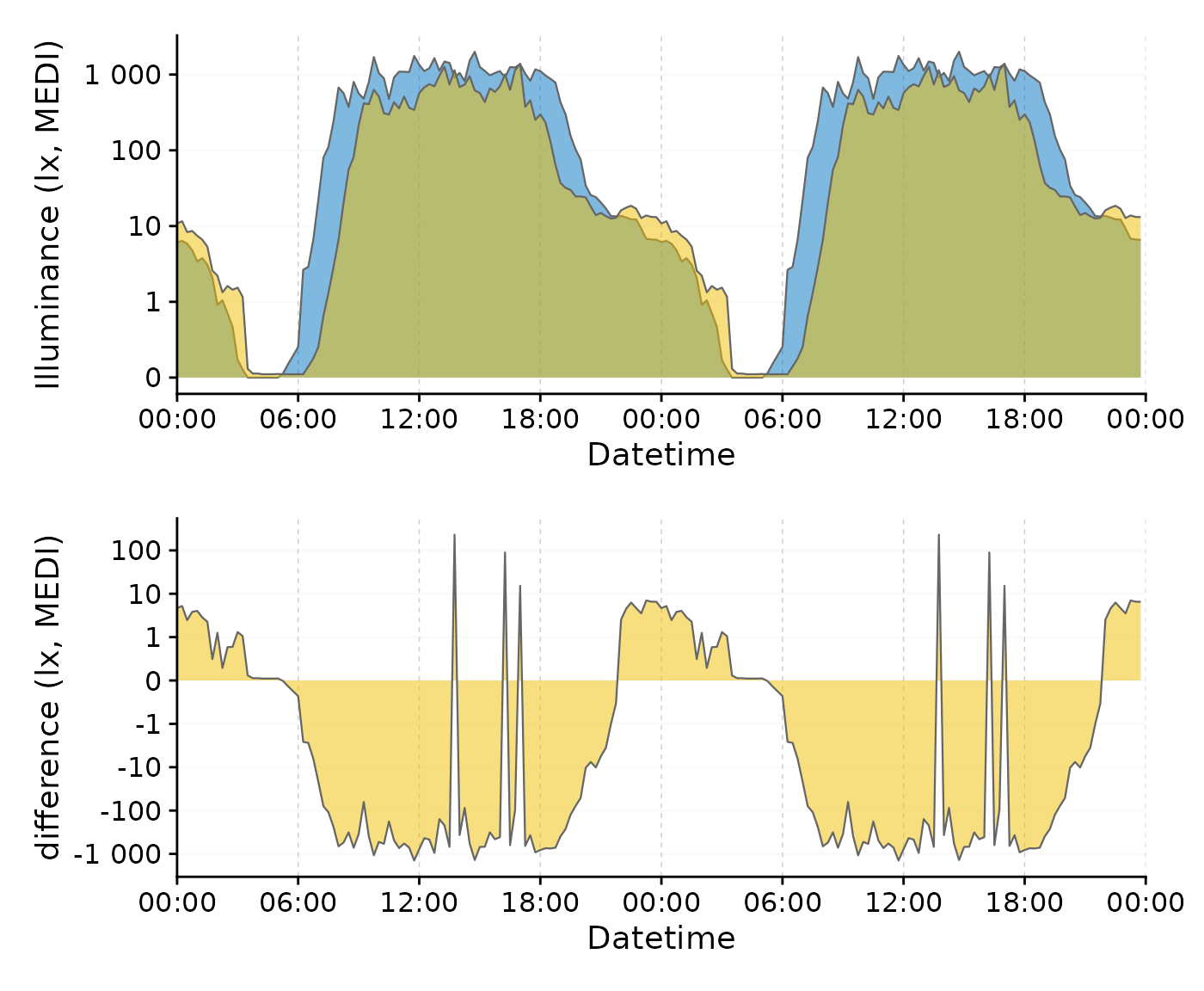
We can further improve this plot. First, we overwrite the default
behavior by setting a specific (arbitrary) date for both groups. By
ungrouping the data afterwards, we can plot the two groups in a single
row, making the two times easily comparable. Setting
facetting = FALSE gets rid of the strip label, that
otherwise would show the (arbitrary) date.
data_two_groups |>
aggregate_Date(unit = "15 mins",
date.handler = \(x) as_date("2023-09-15")
) |>
ungroup() |>
gg_doubleplot(aes_fill = Month, jco_color = TRUE, facetting = FALSE)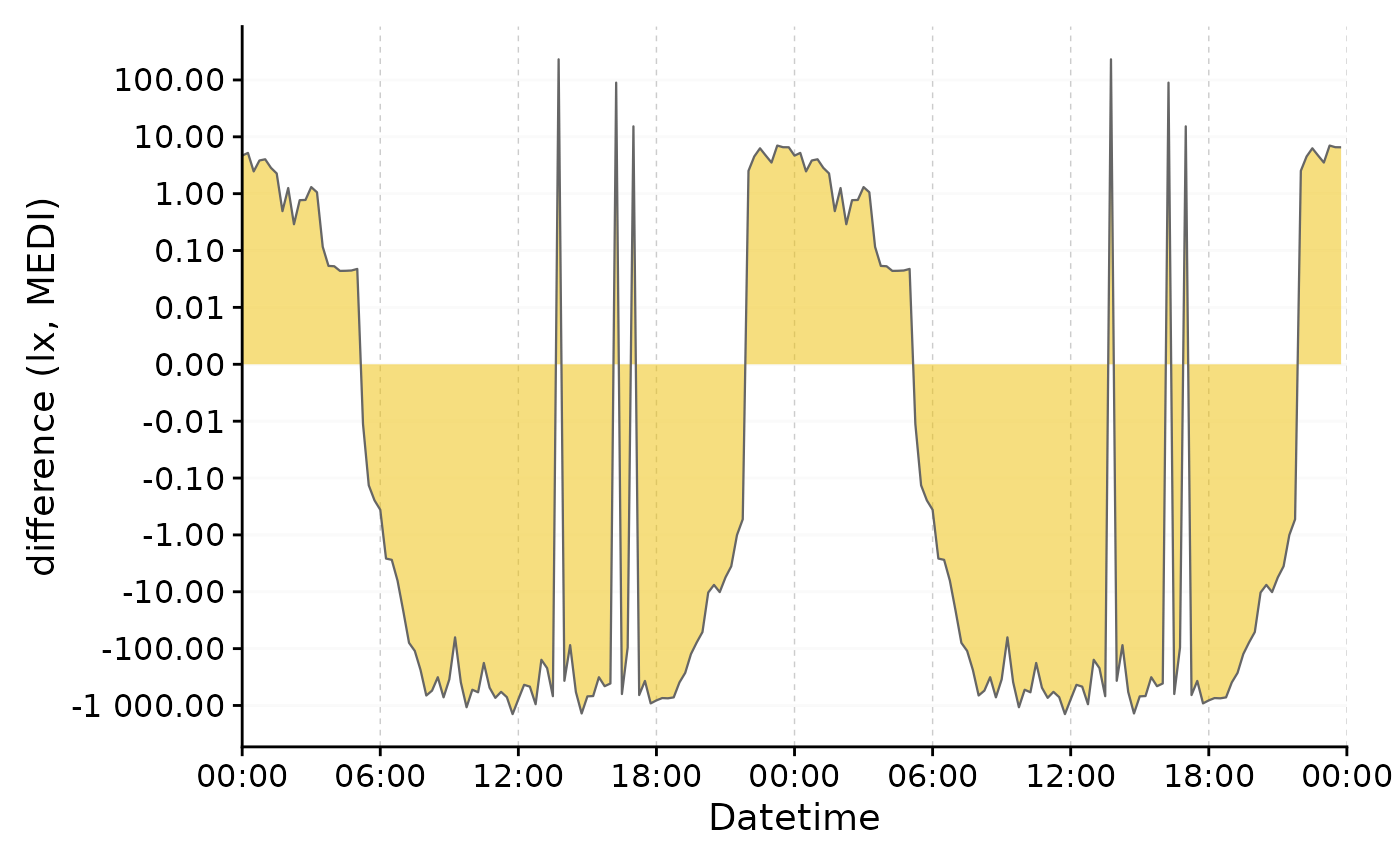
We clearly see now, that daytime light exposure starts later and ends
earlier, with lower daytime values overall. Conversely, nighttime light
exposure is increased in the second half of the experiment (Oct/Nov). By
using the gg_doubleplot() feature, the nighttime light
pattern is clearly visible even accross midnight.
Photoperiod
LightLogR contains a family of functions to calculate
and work with photoperiods. This includes visualization, which is as
easy as adding gg_photoperiod() to your choice of
gg_day(), gg_days(), or
gg_doubleplot(). Here is a minimal example:
#specifying coordinates (latitude/longitude)
coordinates <- c(48.521637, 9.057645)
sample.data.environment |>
gg_days() |>
gg_photoperiod(coordinates) 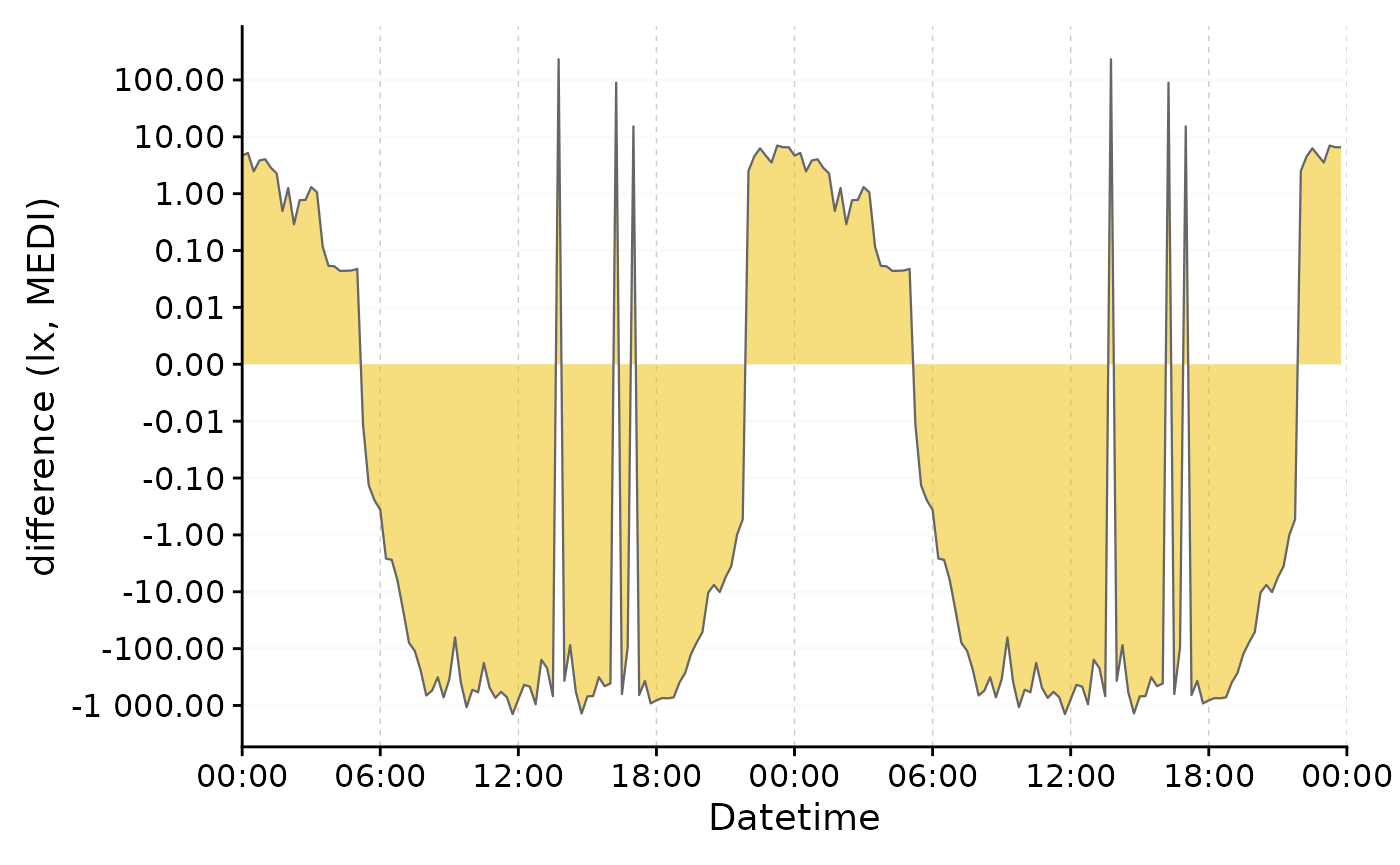
More information on dealing with photoperiods can be found in the article Photoperiod.
gg_states()
gg_states() is another great add on plotting function
that works similarly to gg_photoperiod() in that it is
called on top of an existing plot. Let us start by filtering the larger
dataset down to that participant.
Preparation
#filter the dataset
data_205 <-
data |> filter(Id == "205") |>
aggregate_Datetime(unit = "5 mins", type = "floor")Next we are importing sleep data for a participant (Id = 205), which
is included in LightLogR:
#the the path to the sleep data
path <- system.file("extdata",
package = "LightLogR")
file.sleep <- "205_sleepdiary_all_20230904.csv"
#import sleep/wake data
dataset.sleep <-
import_Statechanges(file.sleep, path,
Datetime.format = "dmyHM",
State.colnames = c("sleep", "offset"),
State.encoding = c("sleep", "wake"),
Id.colname = record_id,
sep = ";",
dec = ",",
tz = "Europe/Berlin")
#>
#> Successfully read in 14 observations across 1 Ids from 1 Statechanges-file(s).
#> Timezone set is Europe/Berlin.
#> The system timezone is UTC. Please correct if necessary!
#>
#> First Observation: 2023-08-28 23:20:00
#> Last Observation: 2023-09-04 07:25:00
#> Timespan: 6.3 days
#>
#> Observation intervals:
#> Id interval.time n pct
#> 1 205 34860s (~9.68 hours) 1 8%
#> 2 205 35520s (~9.87 hours) 1 8%
#> 3 205 35700s (~9.92 hours) 1 8%
#> 4 205 36000s (~10 hours) 1 8%
#> 5 205 36900s (~10.25 hours) 1 8%
#> 6 205 37020s (~10.28 hours) 1 8%
#> 7 205 37920s (~10.53 hours) 1 8%
#> 8 205 45780s (~12.72 hours) 1 8%
#> 9 205 48480s (~13.47 hours) 1 8%
#> 10 205 49200s (~13.67 hours) 1 8%
#> # ℹ 3 more rowsNext, we add the sleep/wake data to the dataset. While we are at it, we also add the Brown et al. 2022 recommendations for healthy light, which can be extracted from sleep/wake data.
data_205 <-
data_205 |>
interval2state(dataset.sleep |> sc2interval()) |> #add sleep/wake-data
interval2state(
dataset.sleep |> sc2interval() |> sleep_int2Brown(),
State.colname = State.Brown) #add Brown et al. 2022 states
#> Adding missing grouping variables: `Id`With gg_days()
Adding the sleep-wake information to a base plot.
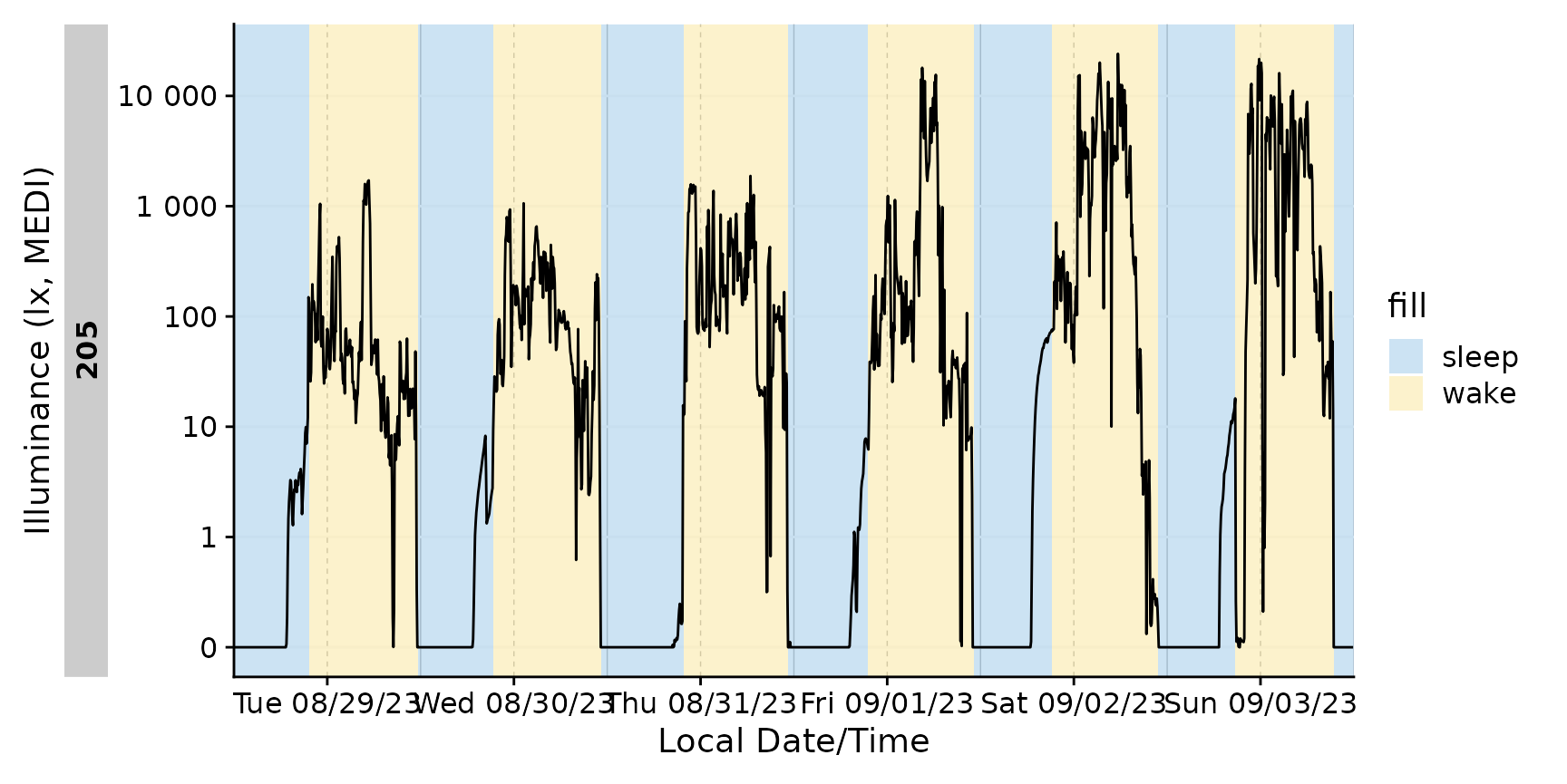
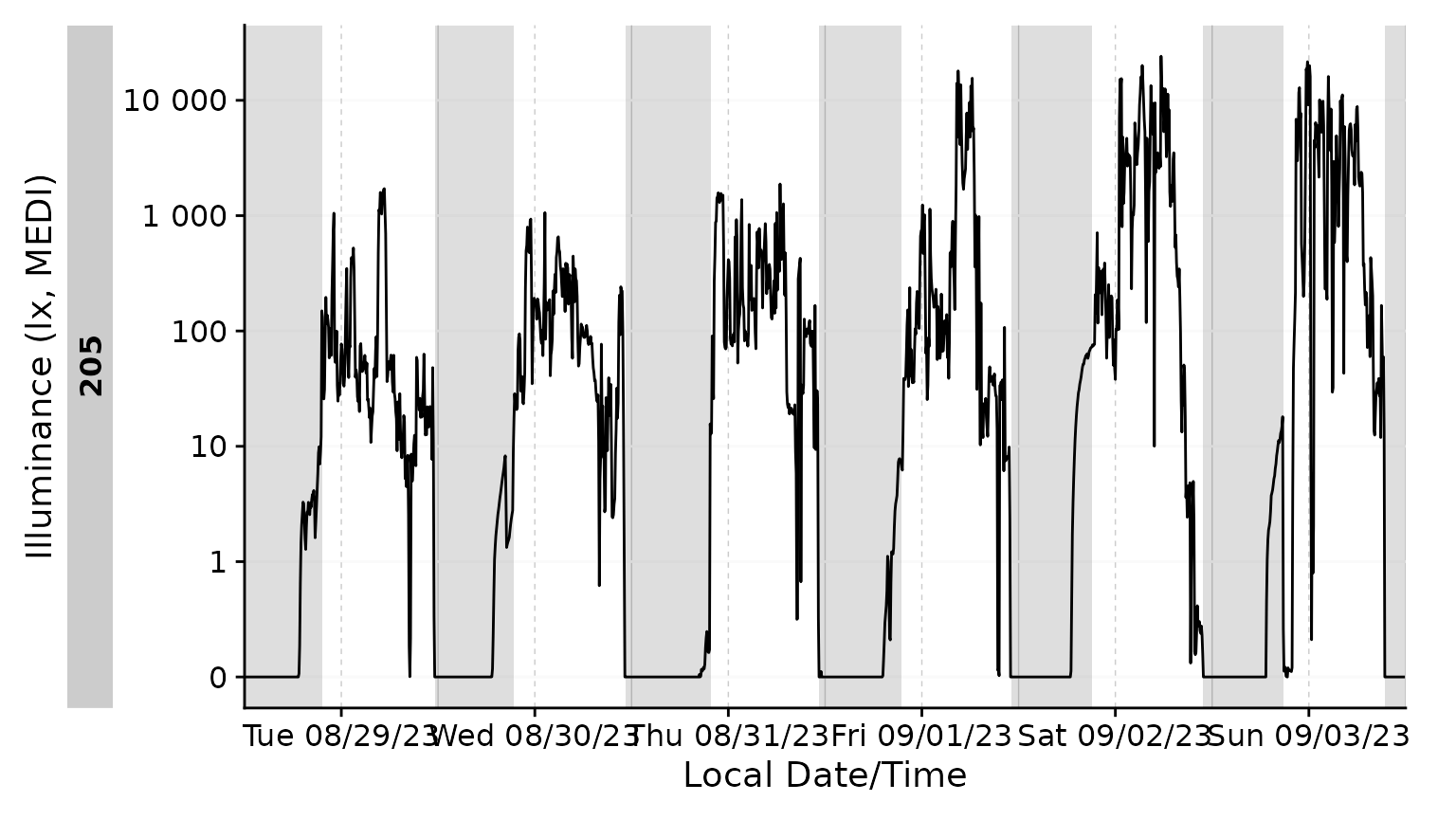
We can also only highlight sleep phases, either by setting
wake instances to NA, or, by converting it to
a logical column. Notice that a conditional fill is no longer
necessary.
With gg_day()
gg_states() automatically detects whether it is called
from gg_day() or gg_days(), so it just works
out of the box.
data_205 |>
gg_day(geom = "line") |>
gg_states(State.Brown, aes_fill = State.Brown) +
labs(fill = "Brown states")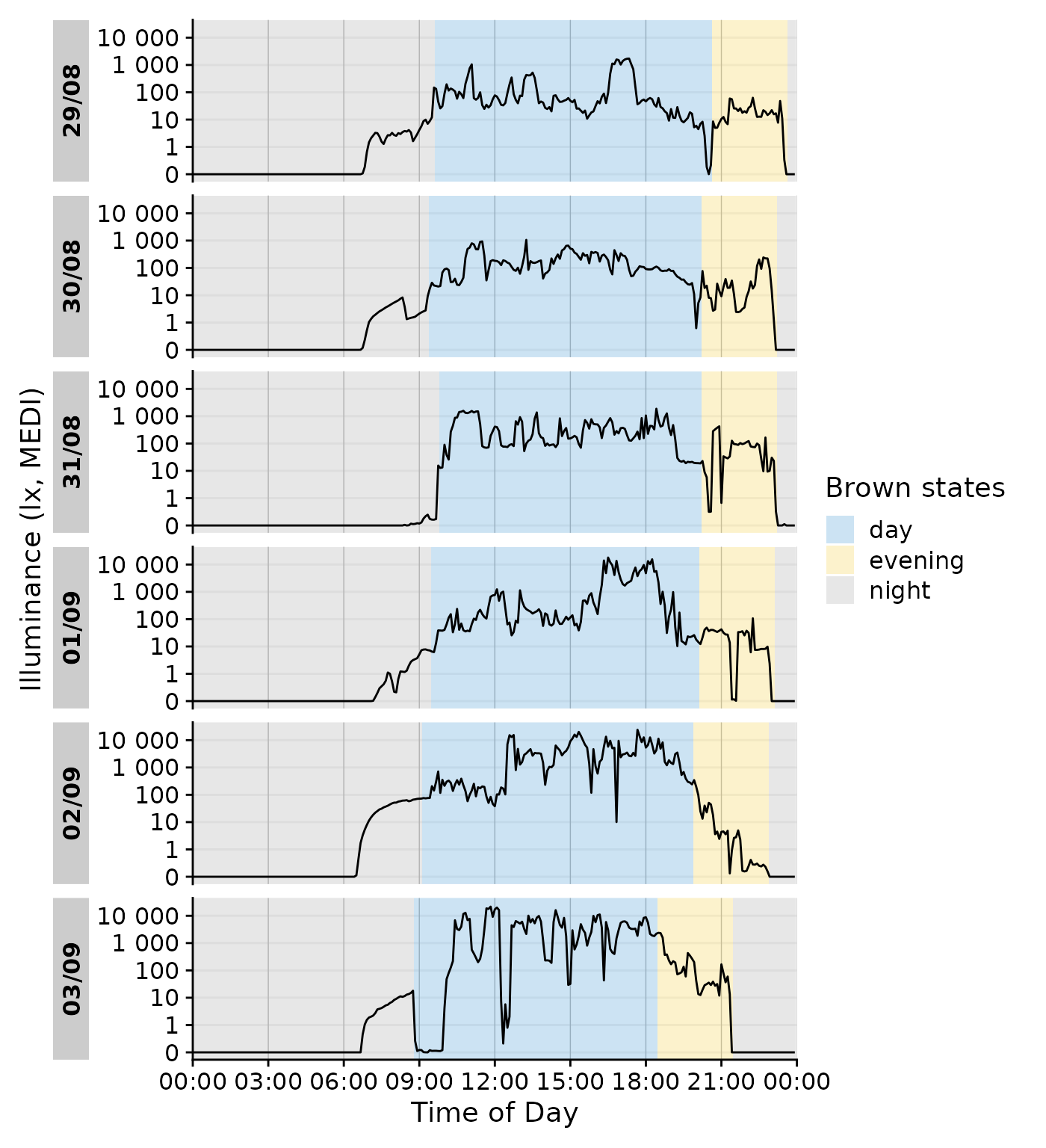
We can even go a step beyond, and show at which times the participant
complied with these recommendations. We will employ the helper function
Brown2reference() that creates additional columns,
including one that tests whether a light exposure level is within the
required range (Reference.check). When we select this
column for gg_states(), we can color by the
State.Brown same as above, but get the selection of when
this recommendation was actually met.
data_205 |>
Brown2reference() |>
group_by(State.Brown, .add = TRUE) |>
gg_day(geom = "line") |>
gg_states(Reference.check, aes_fill = State.Brown) +
labs(fill = "Brown states")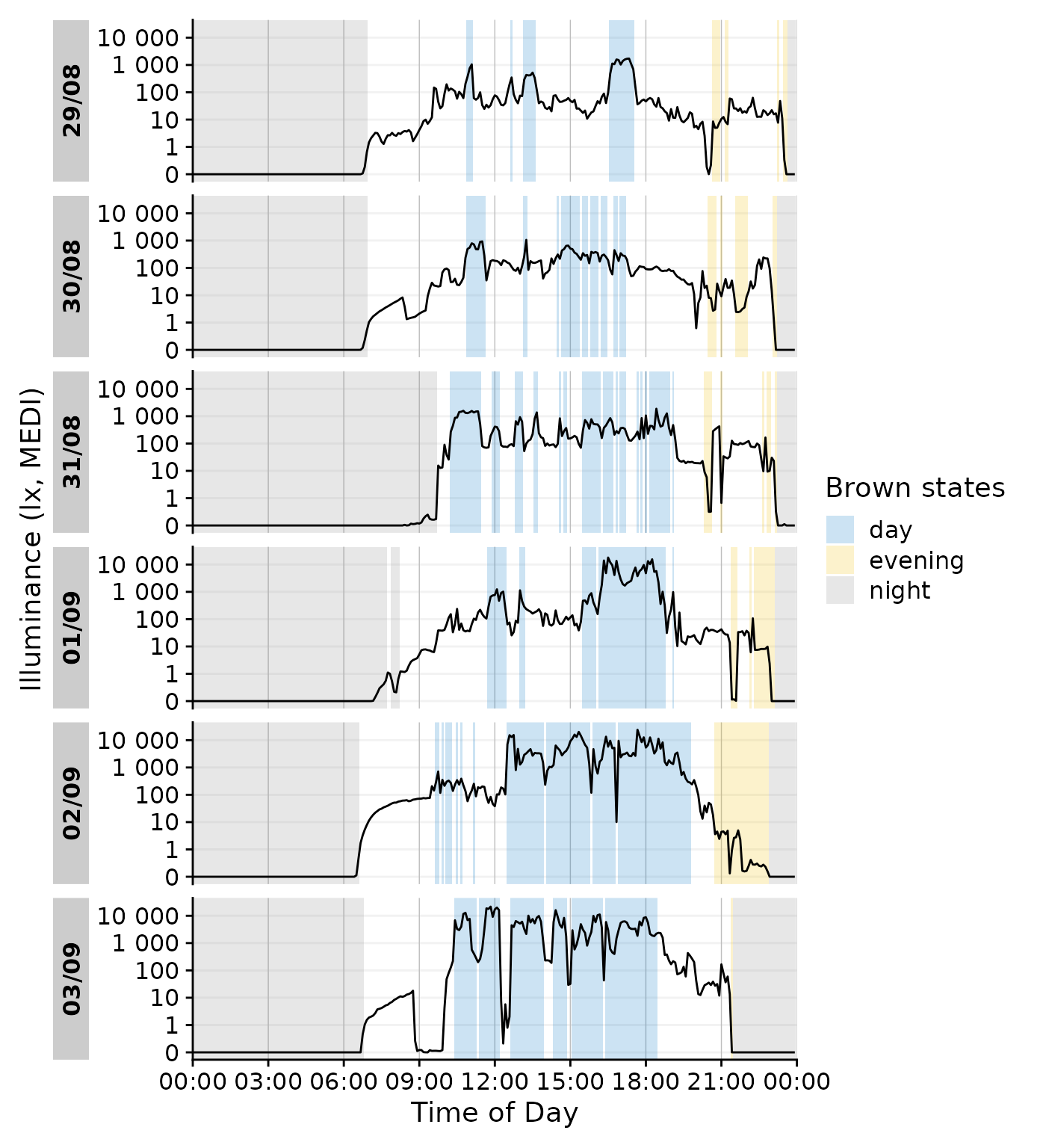
With gg_doubleplot()
gg_states() should mostly work fine with
gg_doubleplot() out of the gate
data_205 |>
mutate(State = ifelse(State == "sleep", TRUE, FALSE)) |>
gg_doubleplot() |>
gg_states(State)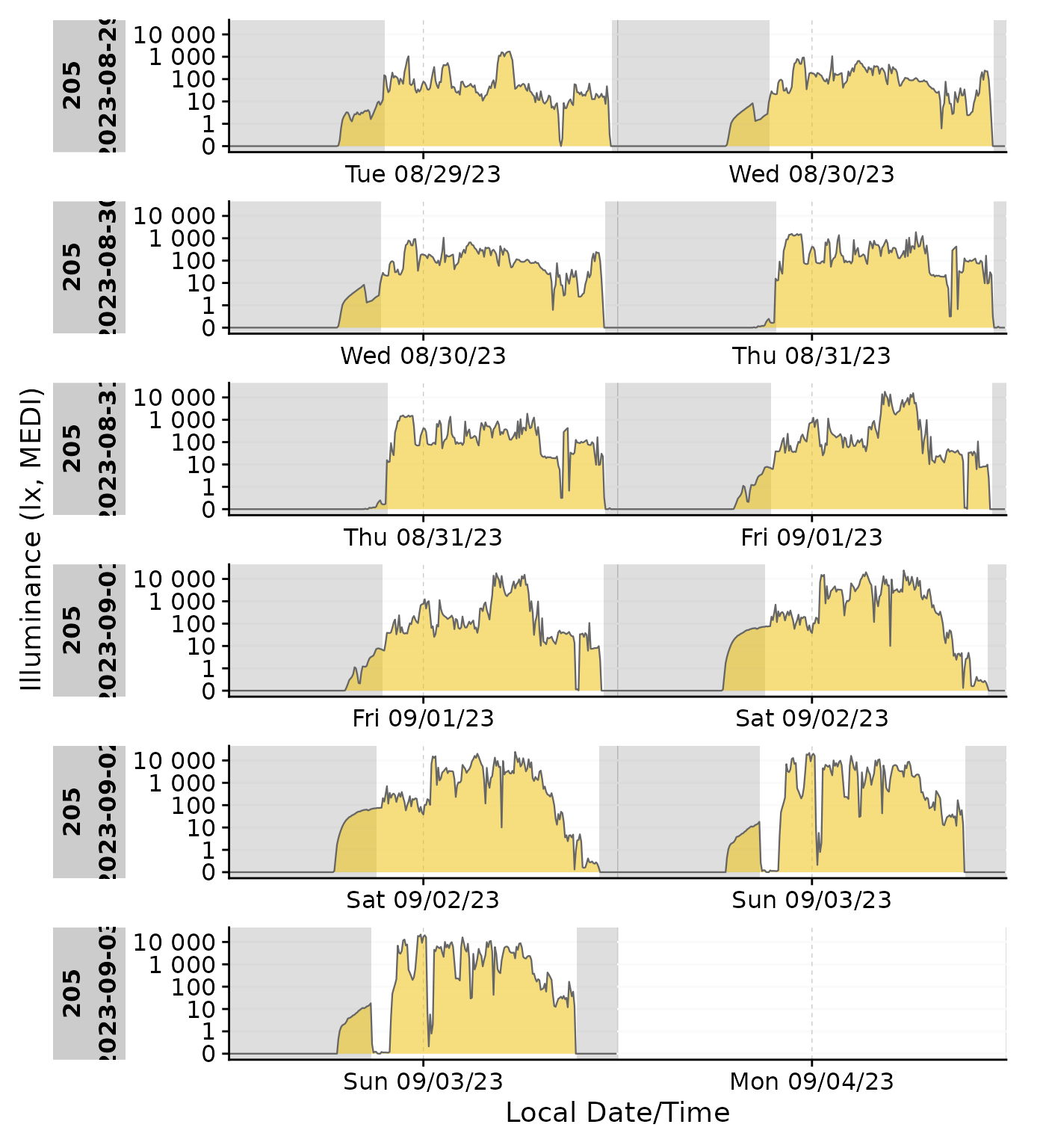
Combination with other add-on functionality
State plotting can be combined with other add-on plotting functions, like other states, photoperiods, or even gaps. However it can quickly become confusing if there are overlapping states, like sleep and nighttime:
data_205 |>
mutate(State = ifelse(State == "sleep", TRUE, FALSE)) |>
gg_doubleplot() |>
gg_states(State, aes_fil = State, aes_col =State, alpha = 0.1) |>
gg_photoperiod(c(48.5,9)) +
labs(colour ="Sleep", fill = "Sleep")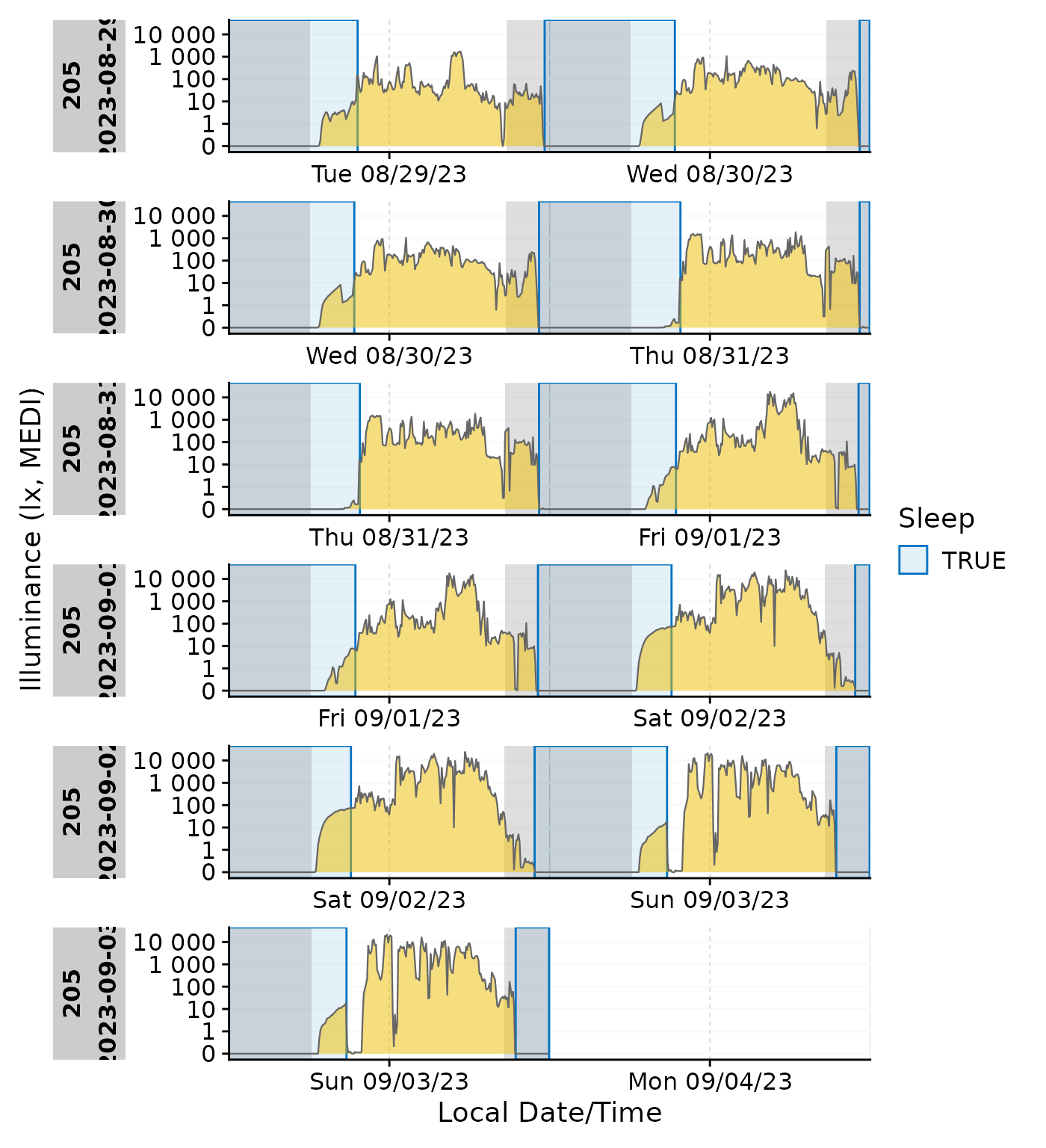
In these cases it might be more useful to color the ribbon according to the state or the photoperiod.
Emphasis ond photoperiod with sleep/wake
data_205 |>
mutate(State = ifelse(State == "sleep", TRUE, FALSE)) |>
add_photoperiod(c(48.5,9)) |>
gg_doubleplot(aes_fill = photoperiod.state, group = consecutive_id(photoperiod.state)) |>
gg_states(State) +
labs(fill = "Photoperiod")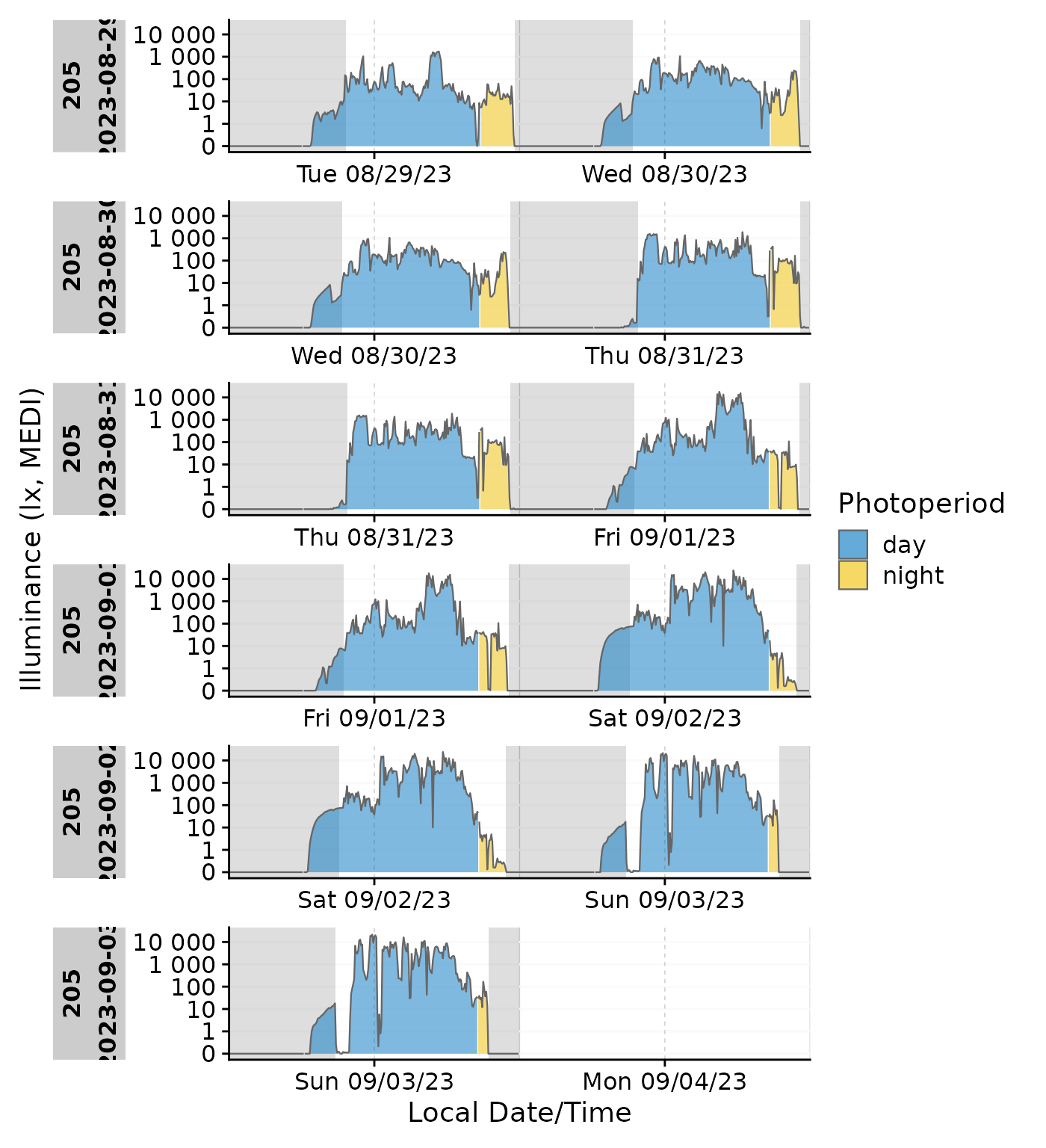
Emphasis on sleep/wake with photoperiod
data_205 |>
gg_doubleplot(aes_fill = State, group = consecutive_id(State)) |>
gg_photoperiod(c(48.5,9)) +
labs(fill = "Sleep")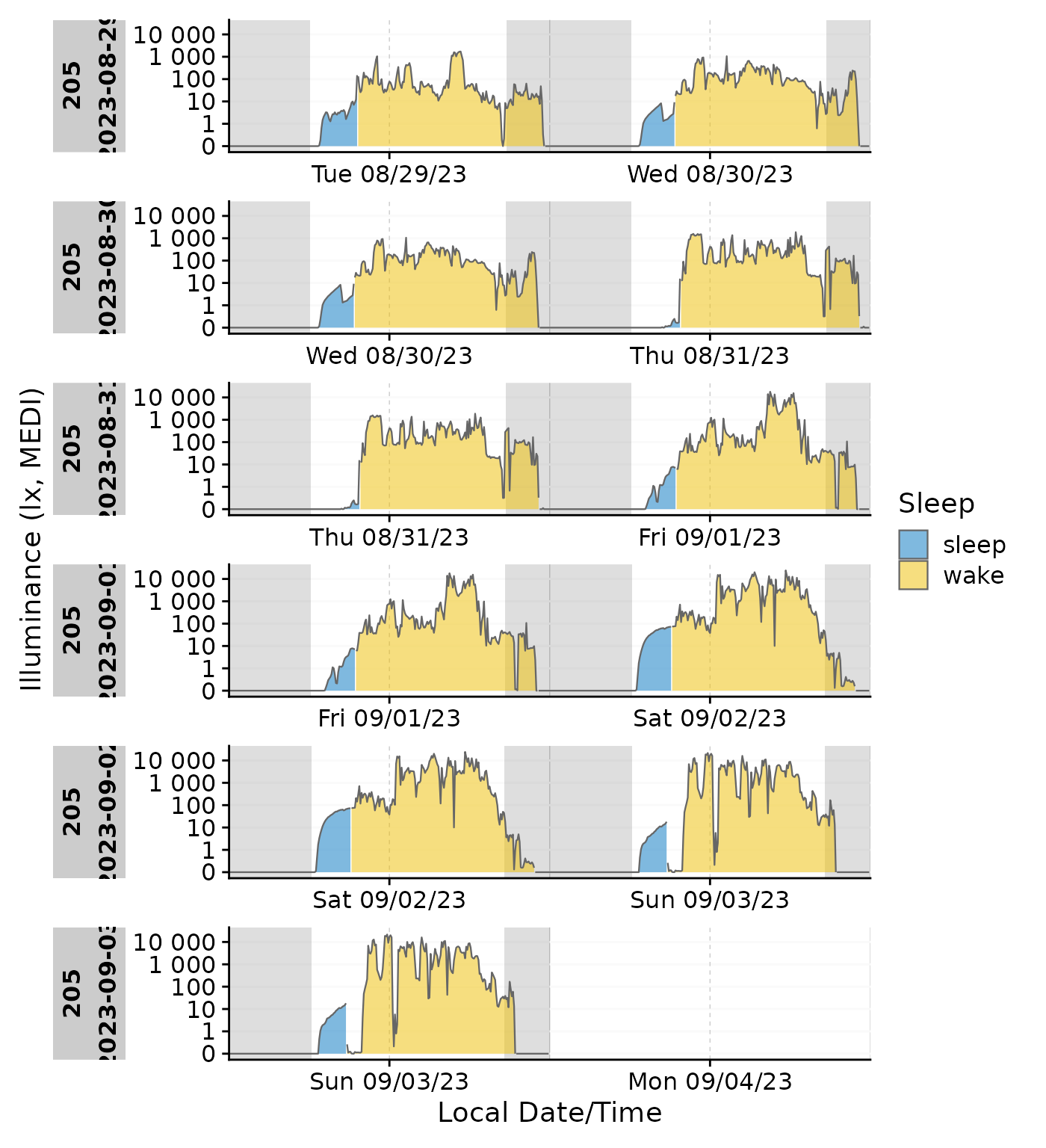
gg_gaps()
gg_gaps() visualizes gaps and optionally also irregular
data. It is easy to use, but can be computationally expensive, if there
are lots of irregular data and/or gaps. Calling it on good data does
produce a plot
data |> gg_gaps()
#> No gaps nor irregular values were found. Plot creation skippedWe can create a dataset with explicit and implicit gaps and irregular
data, where all zero values are replaced with NA,
observations above 1000 lx are missing, and the last day has a slightly
delayed sequence.
bad_dataset <-
data_205 |>
mutate(Datetime = if_else(date(Datetime) == max(date(Datetime)),
Datetime, Datetime + 1), #creates irregular data for the last day
MEDI = na_if(MEDI, 0) #creates explicit gaps
) |>
filter(MEDI <1000) #creates implicit gaps
bad_dataset |> gg_gaps(MEDI)
#> Warning: Removed 113 rows containing missing values or values outside the scale range
#> (`geom_line()`).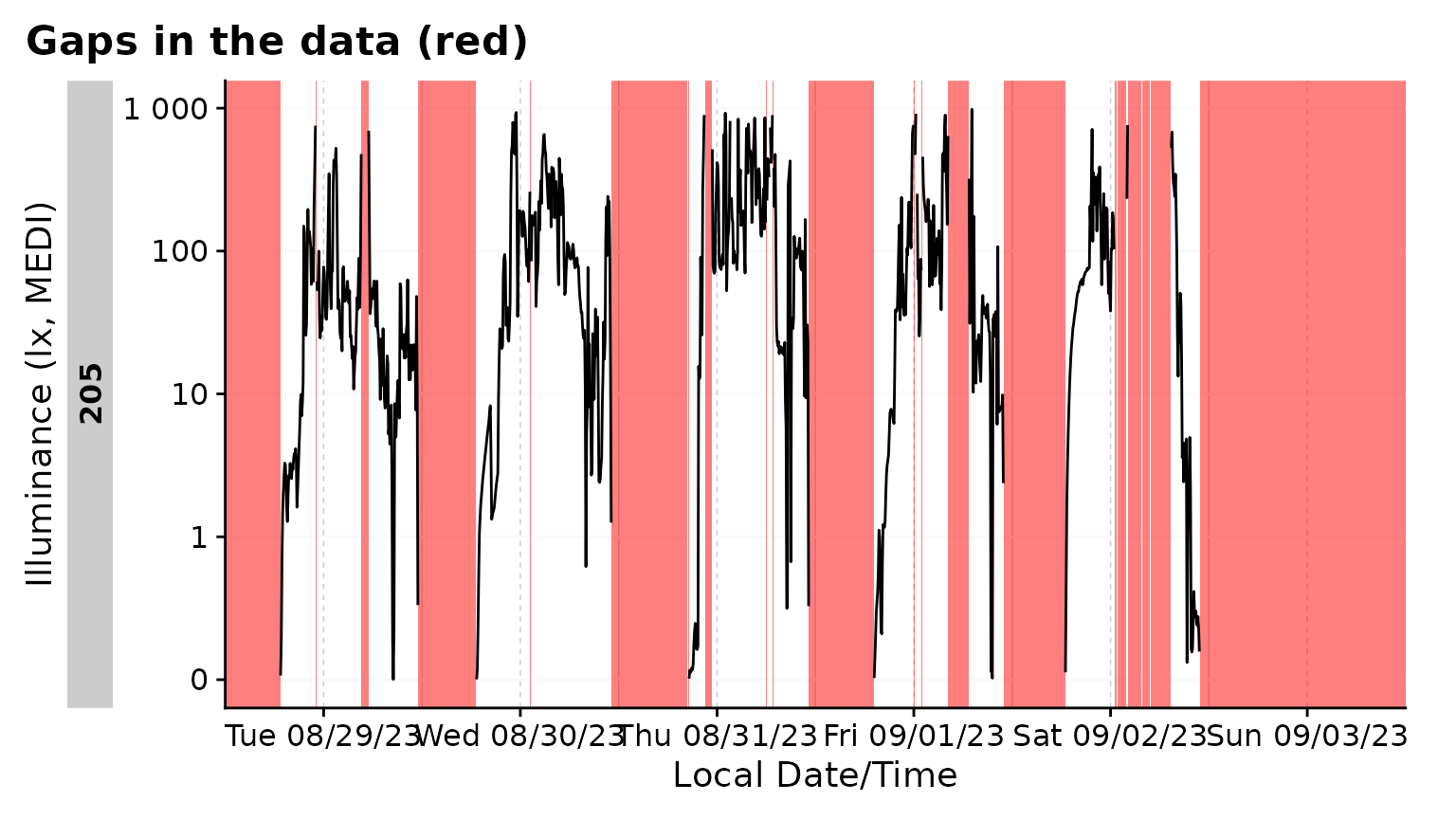 By default,
By default, gg_gaps() only shows missing values. Setting
show.irregulars = TRUE also adds the irregular data to the
plot
bad_dataset |> gg_gaps(MEDI, show.irregulars = TRUE)
#> Warning: Removed 113 rows containing missing values or values outside the scale range
#> (`geom_line()`).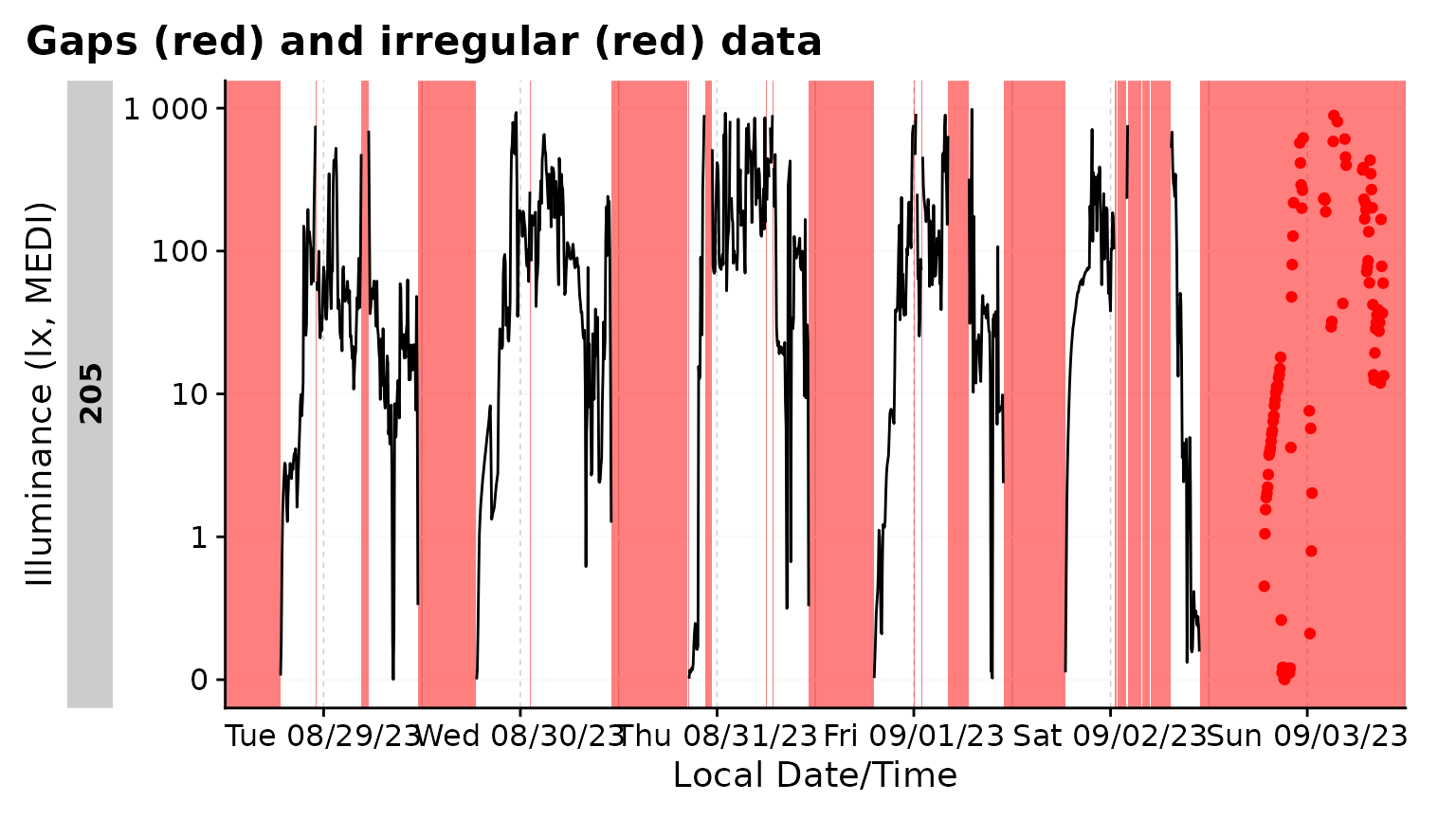
Interactivity
gg_day() and gg_days() have the inbuilt
option to be displayed interactively. This is great for exploring the
data. The plotly package is used for this. They have the
interactive argument set to FALSE by default.
Setting it to TRUE will create an interactive plot.
data_subset |>
gg_day(aes_col = Id, geom = "line",
interactive = TRUE
)Miscellaneous
Non-Light properties
LightLogR is designed to work with light data, but it
can also be used for other types of data. Simply define the y.axis
argument in the plotting functions. In the following example, we will
plot the activity data from the data dataset.
For comparison, the light data is added in the background with a lower alpha value.
data_subset2 |>
gg_days(y.axis = PIM, y.axis.label = "Activity (PIM)") +
geom_line(aes(y=MEDI), color = "red", alpha = 0.2)
Scales
By default, LightLogR uses a so-called
symlog scale for visualizations. This scale is a
combination of a linear and a logarithmic scale, which is useful for
light data, as it allows to visualize very low and very high values in
the same plot, including 0 and negative values. As light data is
regularly zero, and exact values between 0 and 1 lux are usually not as
relevant for devices measuring up to 10^5 lx, this scale is more useful
compared to a linear or logarithmic scaling.
The way symlog works is that there is a threshold up to
which absolute values are kept linear, and beyond which they are
transformed logarithmically. The default threshold is 1, which is a good
choice for light data. However, this can be changed by setting the
threshold argument in the plotting functions. See a full
documentation of the symlog scale
symlog_trans().
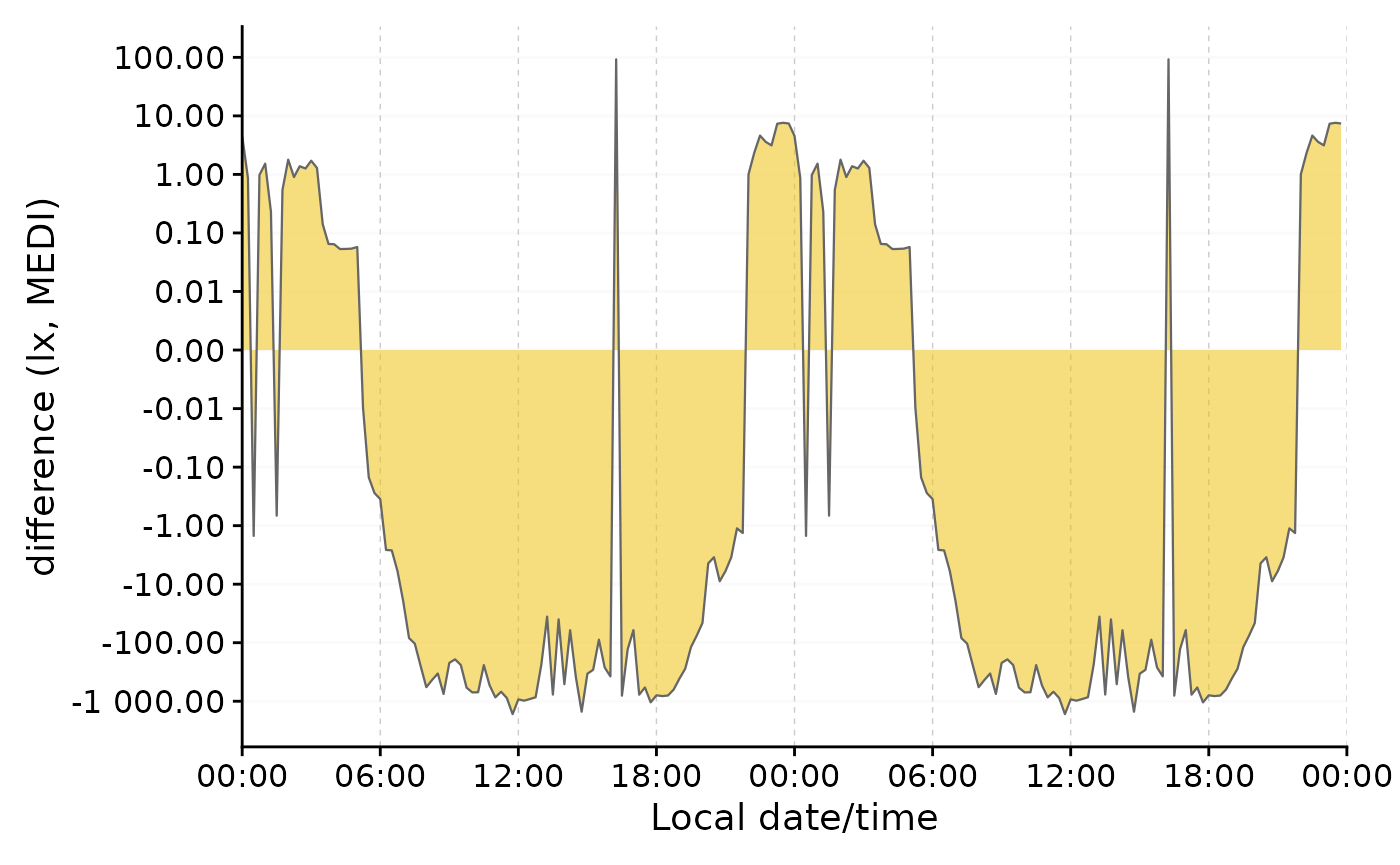
Here is an example to show how the transformation is particularly useful for differences that cross zero. We will use the single-day doubleplot data from above.
#dataset from above
data <-
data_two_groups |>
aggregate_Date(unit = "15 mins",
date.handler = \(x) as_date("2023-09-15")
) |>
ungroup()
#original doubleplot from above
original_db <-
data |>
gg_doubleplot(aes_fill = Month, jco_color = TRUE, facetting = FALSE) +
guides(fill = "none")
#difference doubleplot, showing the average difference between the to phases
difference_db <-
data |>
select(Datetime, MEDI, Month) |>
pivot_wider(names_from = Month, values_from = MEDI) |>
gg_doubleplot(y.axis = `Oct/Nov`-`Aug/Sep`, facetting = FALSE,
y.axis.label = "difference (lx, MEDI)")
#plotting
original_db / difference_db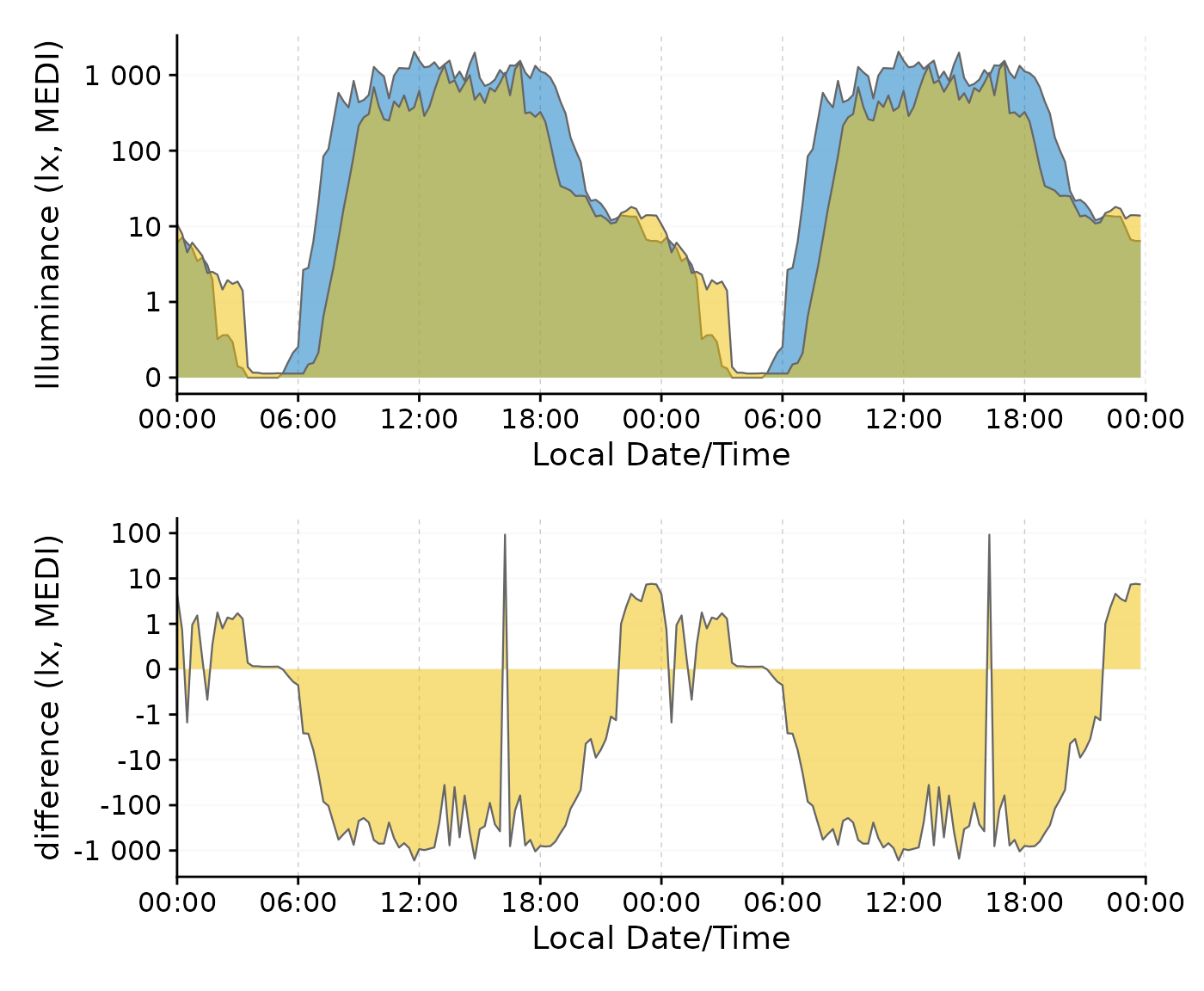
We can clearly see the difference in light exposure is crossing 0 several times. With the symlog scale no values are discarded, because they are outside the traditional range of a logarithmic scale. Should values below 1 lux be of interest, the parameters of the transformation can be adjusted.
data |>
select(Datetime, MEDI, Month) |>
pivot_wider(names_from = Month, values_from = MEDI) |>
gg_doubleplot(y.axis = `Oct/Nov`-`Aug/Sep`, facetting = FALSE,
y.axis.label = "difference (lx, MEDI)",
y.scale = symlog_trans(thr = 0.001),
y.axis.breaks = c(-10^(-2:5), 0, 10^(5:-2))
)