---
title: "Supplement 1"
subtitle: "Analysis of human visual experience data"
author:
- name: "Johannes Zauner"
id: JZ
affiliation:
- Technical University of Munich, Germany
- Max Planck Institute for Biological Cybernetics, Tübingen, Germany
orcid: "0000-0003-2171-4566"
corresponding: true
email: johannes.zauner@tum.de
- name: "Aaron Nicholls"
affiliation: "Reality Labs Research, USA"
orcid: "0009-0001-6683-6826"
- name: "Lisa A. Ostrin"
affiliation: "University of Houston College of Optometry, USA"
orcid: "0000-0001-8675-1478"
- name: "Manuel Spitschan"
affiliation:
- Technical University of Munich, Germany
- Max Planck Institute for Biological Cybernetics, Tübingen, Germany
- Technical University of Munich Institute of advanced study (TUM-IAS), Munich, Germany
orcid: "0000-0002-8572-9268"
doi: 10.5281/zenodo.16566014
format:
html:
toc: true
include-in-header:
- text: |
<style>
.quarto-notebook .cell-container .cell-decorator {
display: none;
}
</style>
number-sections: true
code-tools: true
html-math-method:
method: mathjax
url: "https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.9/latest.js?config=TeX-MML-AM_CHTML"
bibliography: references.bib
lightbox: true
execute:
echo: true
warning: false
---
## Abstract {.unnumbered}
This supplementary document provides a detailed, step-by-step tutorial on importing and preprocessing raw data from two wearable devices: `Clouclip` and `VEET`. We describe the structure of the raw datasets recorded by each device and explain how to parse these data, specify time zones, handle special sentinel values, clean missing observations, regularize timestamps to fixed intervals, and aggregate data as needed. All original R code from the [main tutorial](index.qmd) is shown here for transparency, with additional guidance intended for a broad research audience. We demonstrate how to detect gaps and irregular sampling, convert implicit missing periods into explicit missing values, and address device-specific quirks such as the `Clouclip`’s use of sentinel codes for “sleep mode” and “out of range” readings. Special procedures for processing the `VEET`’s rich spectral data (e.g. normalizing sensor counts and reconstructing full spectra from multiple sensor channels) are also outlined. Finally, we show how to save the cleaned datasets from both devices into a single R data file for downstream analysis. This comprehensive walkthrough is designed to ensure reproducibility and to assist researchers in understanding and adapting the data pipeline for their own visual experience datasets.
## Introduction
Wearable sensors like the `Clouclip` and the Visual Environment Evaluation Tool (`VEET`) produce high-dimensional time-series data on viewing distance and light exposure. Proper handling of these raw data is essential before any analysis of visual experience metrics. In the [main tutorial](index.qmd), we introduce an analysis pipeline using the open-source R package LightLogR [@Zauner2025JOpenSourceSoftw] to calculate various distance and light exposure metrics. Here, we present a full account of the data import and preparation steps as a supplement to the methods, with an emphasis on clarity for researchers who may be less familiar with data processing in R. @fig-fc_supplement shows the main pre-processing steps and how they relate.
{{< include _flowchart_supplement.qmd >}}
We use example datasets from a `Clouclip` device [@Wen2021ActaOphtalmol; @Wen2020bjophthalmol] and from a `VEET` device [@Sah2025OphtalmicPhysiolOpt] (both provided in the accompanying [repository](https://github.com/tscnlab/ZaunerEtAl_JVis_2026)). The `Clouclip` is a glasses-mounted sensor that records working distance (distance from eyes to object, in cm) and ambient illuminance (in lux) at 5-second intervals. The `VEET` is a head-mounted multi-modal sensor that logs ambient light and spectral information (along with other data like motion and distance via a depth sensor) - in this exemplary case at 2-second intervals. A single week of continuous data illustrates the contrast in complexity: approximately 2 MB for the `Clouclip`’s simple three-column output versus up to 270 MB for the `VEET`’s multi-channel output (due to its higher sampling rate and richer sensor modalities).
In the following sections, we detail how these raw data are structured and how to import and preprocess them using LightLogR. We cover device-specific considerations such as file format quirks and sensor range limitations, as well as general best practices like handling missing timestamps and normalizing sensor readings. All code blocks can be executed in R (with the required packages loaded) to reproduce the cleaning steps. The end result will be clean, regularized datasets (`dataCC` for Clouclip, `dataVEET` for VEET light data, `dataVEET2` for VEET spectral data, and `dataVEET3` for VEET distance) ready for calculating visual experience metrics. We conclude by saving these cleaned datasets into a single file for convenient reuse.
## `Clouclip` Data: Raw Structure and Import
The `Clouclip` device exports its data as a text file (not a true Excel file despite sometimes using an .xls extension), which is actually tab-separated values. See @fig-Clouclip_file for the structure of this type of file.
The dataset we will be using comes from a data collection during COVID-19 (November 2020). The dataset was obtained from a 30-year-old male graduate student in the United States and was previously presented as part of a published study. The light exposure profile reflects relatively limited time outdoors, which is consistent with patterns reported in individuals engaged in intensive academic training. [@bhandari2021]
{#fig-Clouclip_file width="35%"}
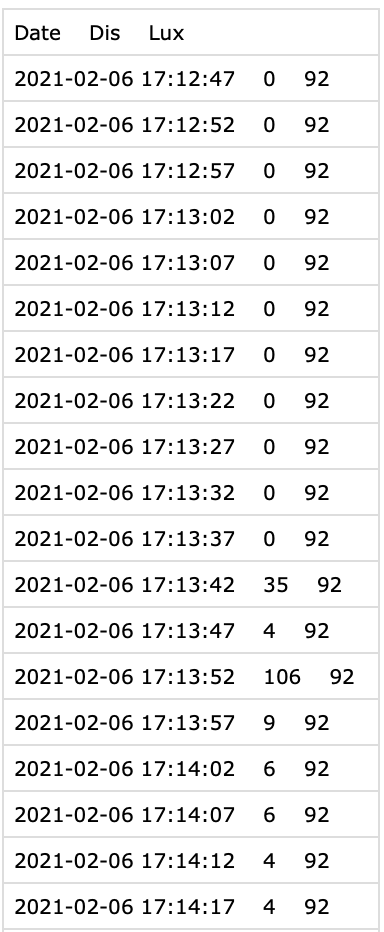
Each record corresponds to one timestamped observation (nominally every 5 seconds) and includes two measured variables: **distance** and **illuminance**. In the sample dataset (`Sample_Clouclip.csv` provided), the columns are:
- `Date` – the date and time of the observation (in the device’s local time).
- `Dis` – the viewing distance in centimeters.
- `Lux` – the ambient illuminance in lux.
For example, a raw data line might look like:
```
2021-07-01 08:00:00 45 320
```
indicating that at *2021-07-01 08:00:00* local time, the device recorded a working distance of 45 cm and illuminance of 320 lx. The Clouclip uses special **sentinel values**[^1] in these measurement columns to denote certain device states. Specifically, a distance (`Dis`) value of **204** is a code meaning the object is *out of the sensor’s range*, and a value of **-1** in either `Dis` or `Lux` indicates the device was in *sleep mode* (not actively recording). During normal operation, distance measurements are limited by the device’s range, and illuminance readings are positive lux values. Any sentinel codes in the raw file need to be handled appropriately, as described below.
[^1]: A *sentinel value* is a special placeholder value used in data recording to signal a particular condition. It does not represent a valid measured quantity but rather acts as a marker (for example, “device off” or “value out of range”).
We will use `LightLogR`’s built-in import function for `Clouclip`, which automatically reads the file, parses the timestamps, and converts sentinel codes into a separate status annotation. To begin, we load the necessary libraries and import the raw `Clouclip` dataset:
```{r}
#| label: setup
#| output: false
#| filename: Load required packages
library(tidyverse) #<1>
library(LightLogR) #<2>
library(gt) #<3>
library(ggridges) #<4>
library(downlit) #<5>
library(magick) #<5>
```
1. For tidy data science
2. Wearable analysis package
3. For great tables
4. For ridgeline plots
5. These packages are not used, but are needed for dependencies
```{r}
#| label: fig-importCC
#| filename: Import of Clouclip data
#| fig-cap: "Overview plot of imported Clouclip data"
#| fig-height: 2
#| fig-width: 6
path <- "data/Sample_Clouclip.csv" #<1>
tz <- "US/Central" #<2>
dataCC <- import$Clouclip(path, tz = tz, manual.id = "Clouclip") #<3>
```
1. Define file path
2. Time zone in which device was recording (e.g., US Central Time)
3. Import Clouclip data
In this code, `import$Clouclip()` reads the tab-delimited file and returns a **tibble**[^2] (saved in the variable `dataCC`) containing the data. We specify `tz = "US/Central"` because the device’s clock was set to U.S. Central time; this ensures that the `Datetime`values are properly interpreted with the correct time zone. The argument `manual.id = "Clouclip"` simply tags the dataset with an identifier (useful if combining data from multiple devices).
[^2]: **tibble** are data.tables with tweaked behavior, ideal for a tidy analysis workflow. For more information, visit the documentation page for [tibbles](https://tibble.tidyverse.org/index.html)
During import, LightLogR automatically handles the `Clouclip`’s sentinel codes. The `Date` column from the raw file is parsed into a `POSIXct` date-time (`Datetime`) with the specified time zone. The `Lux` and `Dis` columns are read as numeric, but any occurrences of **-1** or **204** are treated specially: these are replaced with `NA` (missing values) in the numeric columns, and corresponding status columns `Lux_status` and `Dis_status` are created to indicate the reason for those `NA` values. For example, if a `Dis` value of *204* was encountered, that row’s `Dis` will be set to NA and `Dis_status` will contain `"out_of_range"`; if `Lux` or `Dis` was -1, the status is `"sleep_mode"`. We will set all other readings to `"operational"` (meaning the device was functioning normally at that time) for visualisation purposes.
```{r}
#| filename: Print the first 6 rows of the Clouclip dataset
dataCC |> head()
```
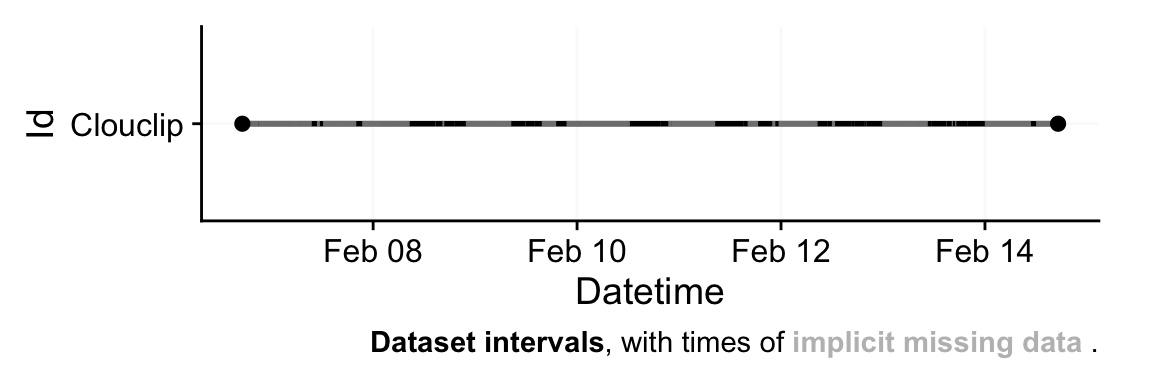
After import, it is good practice to get an overview of the data. The import function by default prints a brief summary (and generates an overview plot of the timeline) showing the number of observations, the time span, and any irregularities or large gaps. In our case, the `Clouclip` summary indicates the data spans one week and reveals that there are **irregular intervals** in the timestamps. This means some observations do not occur exactly every 5 seconds as expected. We can programmatically check for irregular timing:
```{r}
#| filename: Check if data are on a perfectly regular 5-second schedule
dataCC |> has_irregulars()
```
If the result is `TRUE`, it confirms that the time sequence has deviations from the regular interval. Indeed, our example dataset has many small timing irregularities and gaps (periods with no data). Understanding the pattern of these missing or irregular readings is important. We can visualize them using a gap plot:
```{r}
#| label: fig-irregular
#| filename: Plot gaps and irregular timestamps for Clouclip data
#| fig-height: 12
#| warning: false
#| fig-cap: "Visualization of gaps and irregular data. Black traces show available data. Red shaded areas show times of missing data. Red dots show instances where observations occur off the regular interval from start to finish, i.e., irregular data."
y.label <- "Illuminance (lx)"
dataCC |> gg_gaps(Lux, #<1>
include.implicit.gaps = FALSE, #<2>
show.irregulars = TRUE, #<3>
y.axis.label = y.label,
group.by.days = TRUE,
col.irregular = alpha("red", 0.03)
) + labs(title = NULL)
```
1. Basing the gap-figure on the `Lux` illuminance variable
2. Only show missing observations (`NA` values)
3. Highlight irregular timing
In @fig-irregular, time periods where data are missing appear as red-shaded areas, and any off-schedule observation times are marked with red dots. The `Clouclip` example shows extensive gaps (red blocks) on certain days and irregular timing on all days except the first. These irregular timestamps likely arise from the device’s logging process (e.g. slight clock drift or buffering when the device was turned on/off). Such issues must be addressed before further analysis.
::: callout-note
### Why are we using illuminance to handle gaps instead of distance?
Usind distance would have worked just as well for `gap_handler()` and the subsequent functions used here. However, there are actual recordings in the `ClouClip` data for distance that have a missing value due to being `Out of bounds`. We are, however, rather interested in the times when there is no time stamp at all. Here, illuminance is the safer bet.
:::
When faced with irregular or gapped data, we recommend a few strategies:
- *Remove leading/trailing segments that cause irregularity.* For example, if only the first day is regular and subsequent days drift, one might exclude the problematic portion using date filters (see [filter_Date() / filter_Datetime()](https://tscnlab.github.io/LightLogR/reference/filter_Datetime.html) in LightLogR).
- *Round timestamps to the nearest regular interval.* This relabels slightly off-schedule times back to the 5-second grid (using [cut_Datetime()](https://tscnlab.github.io/LightLogR/reference/cut_Datetime.html) with a 5-second interval), provided the deviations are small and this rounding won’t create duplicate timestamps.
- *Aggregate to a coarser time interval.* For instance, grouping and averaging data into 1-minute bins with [aggregate_Datetime()](https://tscnlab.github.io/LightLogR/reference/aggregate_Datetime.html) can mask irregularities at finer scales, at the cost of some temporal resolution.
In this case, the deviations from the 5-second schedule are relatively minor. We choose to **round the timestamps to the nearest 5 seconds** to enforce a uniform sampling grid, which simplifies downstream gap handling. We further add a separate date column for convenience:
```{r}
#| filename: Regularize timestamps by rounding to nearest 5-second interval
dataCC <- dataCC |>
cut_Datetime("5 secs", New.colname = Datetime) |> #<1>
add_Date_col(group.by = TRUE) #<2>
```
1. Round times to 5-second bins
2. Add a Date column for grouping by day
After this operation, all `Datetime` entries in `dataCC` align perfectly on 5-second boundaries (e.g. **08:00:00**, **08:00:05**, **08:00:10**, etc.). We can verify that no irregular intervals remain by re-running `has_irregulars()`. We also check whether there are duplicate entries:
```{r}
#| filename: Re-check if data are on a perfectly regular 5-second schedule
dataCC |> has_irregulars()
dataCC |> count_difftime() |> ungroup() |> count(difftime, sort = TRUE) #<1>
```
1. `count_difftime()` gives us a summary of all the time differences (`difftime`) between consecutive measurements. `ungroup()` removes all grouping variables, so that `count()` can give us a sorted list of all the time differences. The smallest is `5s`, so there are no duplicate entries - otherwise the smallest would be `0s`.
Next, we want to quantify the missing data. LightLogR distinguishes between **explicit missing values** (actual `NA`s in the data, possibly from sentinel replacements or gaps we have filled in) and **implicit missing intervals** (time points where the device *should* have a reading but none was recorded, and we have not yet filled them in). See @fig-gaps for a visual aid to these terms. Initially, many gaps are still implicit (between the first and last timestamp of each day).
::: {#fig-gaps layout-ncol="2"}
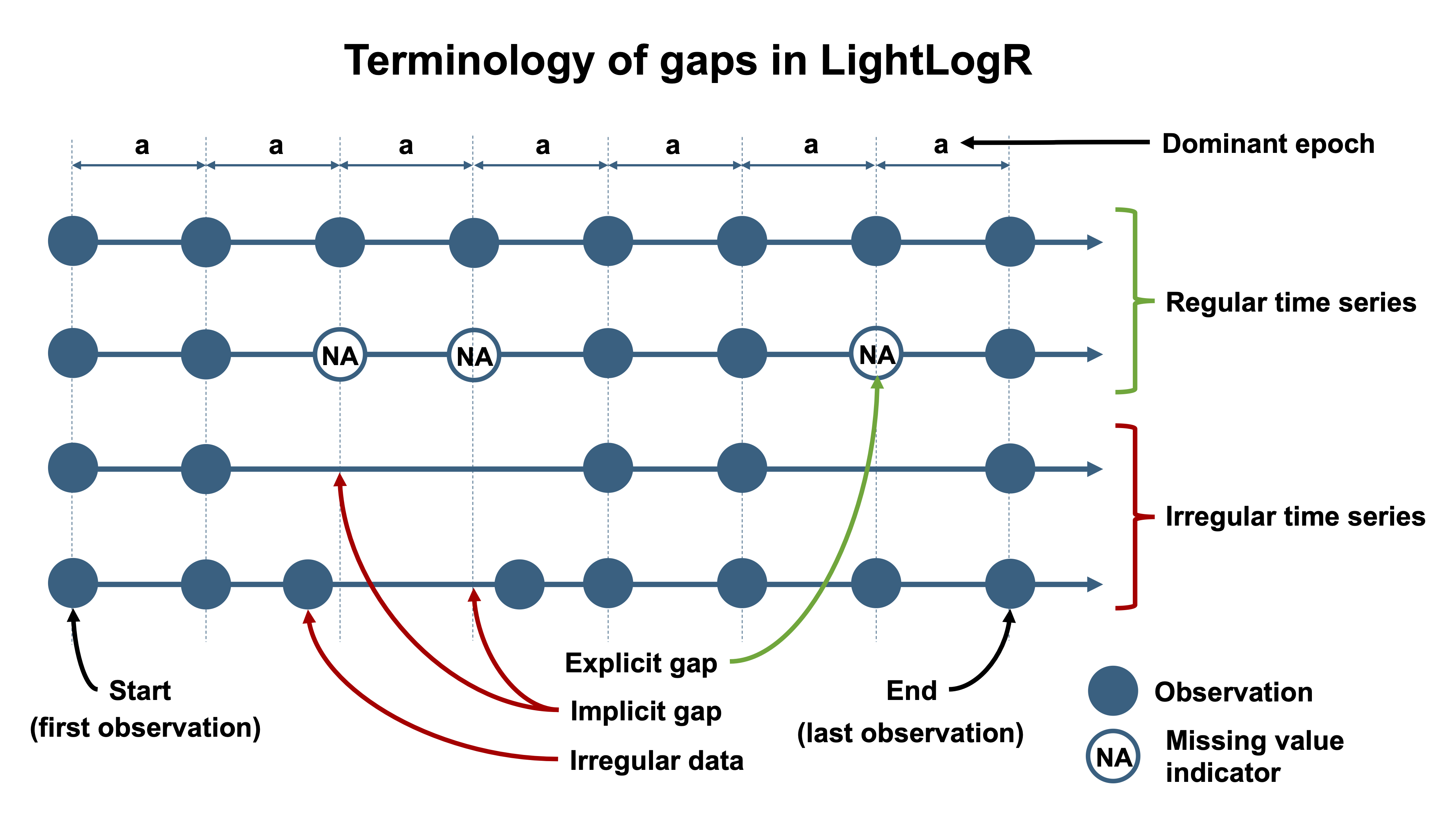
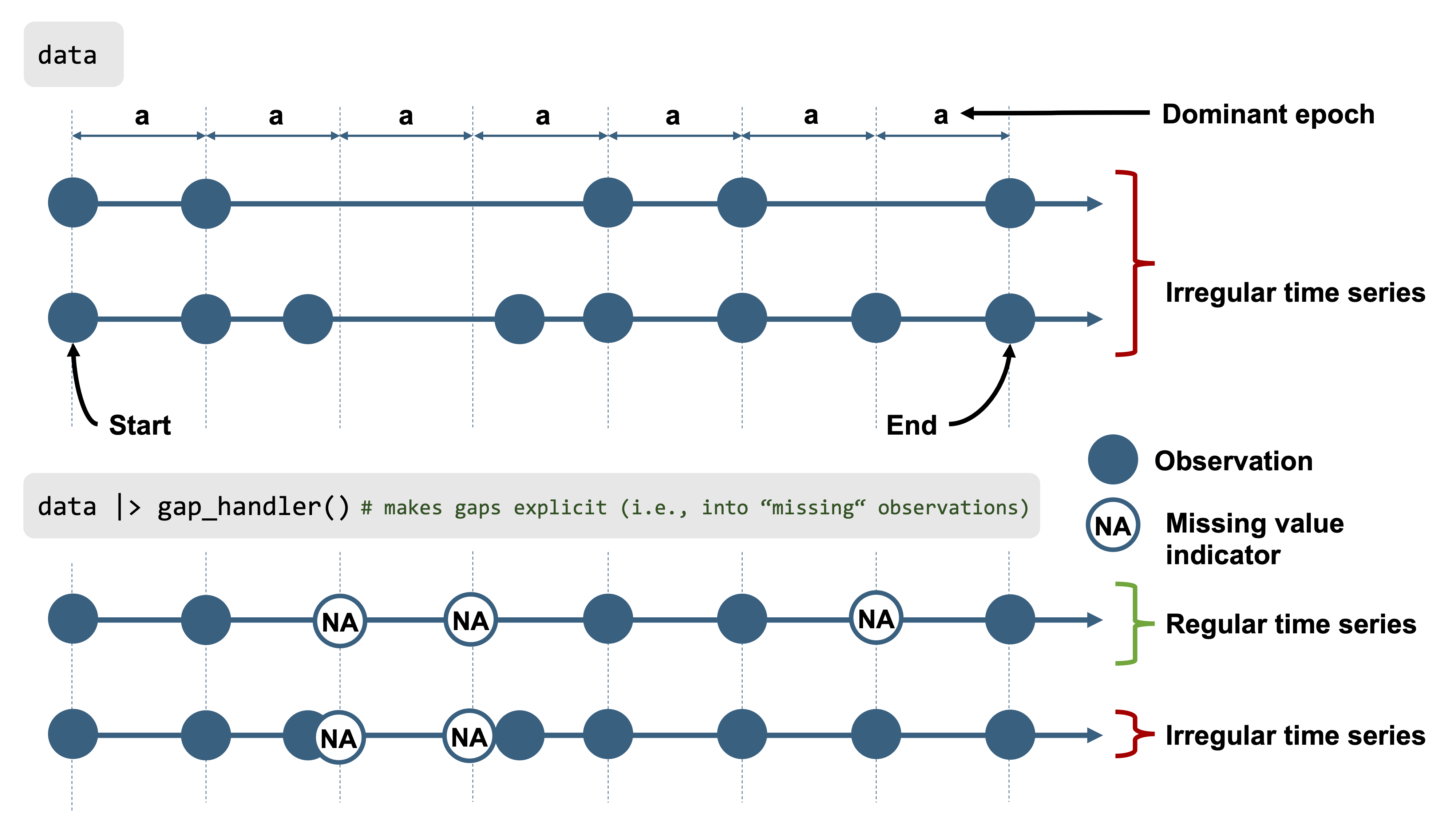
Gaps and irregular data
:::
We can generate a gap summary table:
```{r}
#| label: tbl-gaps
#| tbl-cap: "Summary of missing and observed data for the Clouclip device"
#| filename: Summarize observed vs missing data by day for distance
dataCC |> gap_table(Lux, Variable.label = "Illuminance (lx)") |>
cols_hide(contains("_n")) #<1>
```
1. Hide absolute counts for brevity in output
This summary (@tbl-gaps) breaks down, for each day, how much data is present vs. missing. It reports the total duration of recorded data and the duration of gaps. After rounding the times, there are no irregular timestamp issues, but we see substantial **implicit gaps** — periods where the device was not recording (e.g., overnight when the device was likely not worn or was in sleep mode). Often, the first and last days of a recording period have fewer datapoints, usually because they represent partial recording days (the trial started and ended on those days).
To prepare the dataset for analysis, we will convert all those implicit gaps into explicit missing entries, and remove days that are mostly incomplete. Converting implicit gaps means inserting rows with `NA` for each missing 5-second slot, so that the time series becomes continuous and explicit about missingness (see @fig-gaps). We use `gap_handler()` for this, and then drop the nearly-empty days:
```{r}
#| filename: Convert implicit gaps to explicit NA gaps, and drop days with <1 hour of data
dataCC <- dataCC |>
mutate(across(c(Lux_status, Dis_status), ~ replace_na(.x, "operational"))) |> #<1>
gap_handler(full.days = TRUE) |> #<2>
remove_partial_data(Lux, threshold.missing = "-1 hour") #<3>
```
1. First ensure that status columns have an "operational" tag for non-missing periods
2. Fill in all implicit gaps with explicit NA rows (for full days range)
3. Remove any day that has less than 1 hour of recorded data
After these steps, `dataCC` contains continuous 5-second timestamps for each day that remains. We chose a threshold of “-1 hours” to remove days with less than one hour of data, which in this dataset removes the first and last (partial) days. The cleaned `Clouclip` data now covers six full days with bouts of continuous wear.
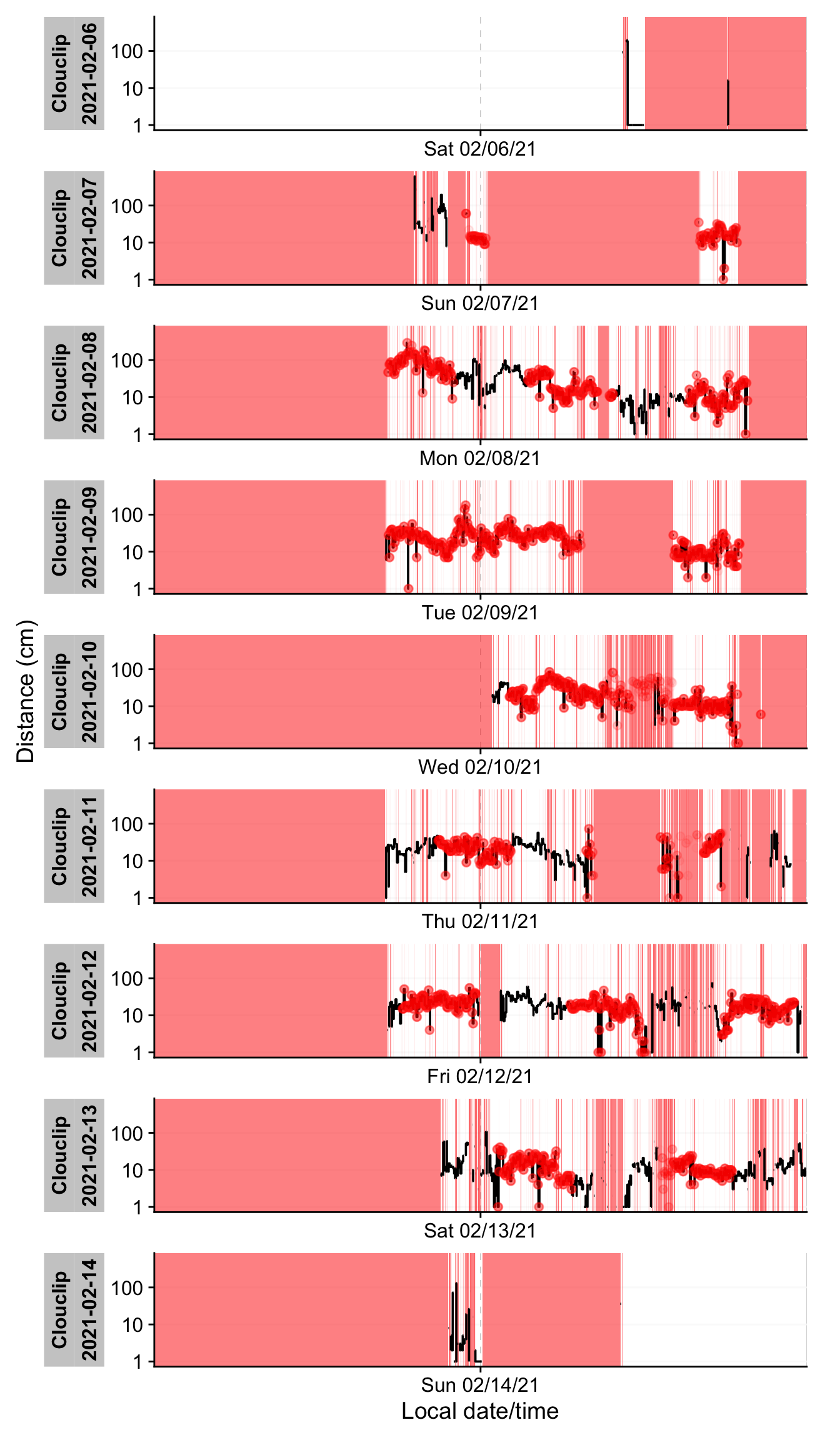
It is often helpful to double-check how the sentinel values and missing data are distributed over time. We can visualize the distance time-series with status annotations and day/night periods:
```{r}
#| fig-height: 8
#| warning: false
#| filename: Visualize observations and sentinel states
#| label: fig-state
#| fig-cap: "Distance measurements across days. Blue, grey and yellow-colored bars at the bottom of each day show sentinel states of the device. Blue indicates an operational status, grey sleep mode (not recording), and yellow an out of range measurement. Shaded areas in the main plot show nighttime from civil dusk until dawn, which are calculated based on the recording date and geographic coordinates"
coordinates <- c(29.75, -95.36) #<1>
dataCC |>
fill(c(Lux_status, Dis_status), .direction = "downup") |> #<2>
gg_day(y.axis = Dis, geom = "line", y.axis.label = "Distance (cm)") |> #<3>
gg_state(Dis_status, aes_fill = Dis_status, ymin = 0, ymax = 0.5, alpha = 1) |> #<4>
gg_photoperiod(coordinates, alpha = 0.1) + #<5>
theme(legend.position = "bottom") +
labs(fill = "Distance status")
```
1. Setting coordinates for Houston, Texas (recording location)
2. Retain status markers until a new marker arrives
3. Create the basic plot
4. Add the status times
5. Add the photoperiod (day/night)
In this plot, there is a `Distance status` in the lower portion of each day. Blue segments indicate times when the Clouclip was *operational* (actively measuring), grey segments indicate the device in *sleep mode* (no recording, typically at night), and yellow segments indicate *out-of-range* distance readings. The large grey regions across the full plot height of each day show nighttime (from civil dusk to dawn) based on the given latitude/longitude and dates. As expected, most of the grey “sleep” periods align with night hours, and we see many yellow spans when the user’s viewing distance exceeded the device’s range (e.g., such as when the user looked into the far distance).
We note many values that far exceed the `Clouplip`s sensitivity range of up to 120 cm. As [@Bhandari2020OphthalmicPhysiolOpt] showed that the measurements start to deviate from actual measurements around 100 cm distance, it is sensible to cap the devices measurements at that point.
```{r}
#| filename: Cap sensor values at 120 cm
dataCC <-
dataCC |>
mutate(
Dis_status = replace_when(Dis_status,
Dis > 120 ~ "over 120cm"),
Dis = replace_when(Dis,
Dis > 120 ~ NA)
)
```
At this stage, the Clouclip dataset `dataCC` is fully preprocessed: all timestamps are regular 5-second intervals, missing data are explicitly marked, extraneous partial days are removed, sentinel codes are handled via the status columns, and values above 120 cm are set to `NA`. The data are ready for calculating daily distance and light exposure metrics (as done in the [main tutorial](index.qmd)’s Results).
## `VEET` Data: Ambient Light (Illuminance) Processing
The **VEET** device [@Sah2025OphtalmicPhysiolOpt, @Sullivan2024] is a more complex logger that records multiple data modalities in one combined file. Its raw data file contains interleaved records for different sensor types, distinguished by a “modality” field. We focus first on the ambient light sensor modality (abbreviated **ALS**), which provides broad-spectrum illuminance readings (lux) and related information like sensor gains and flicker, recorded every 2 seconds. Later we will import the spectral sensor modality (**PHO**) for spectral irradiance data, and the time-of-flight modality (**TOF**) for distance data.
In the `VEET`’s export file, each line includes a timestamp and a modality code, followed by fields specific to that modality. Importantly, this means that the `VEET` export is not rectangular, i.e., tabular (see @fig-VEET_file). This makes it challenging for many import functions that expect the equal number of columns in every row, which is not the case in this instance. For the **ALS modality**, the relevant columns include a high-resolution timestamp (in Unix epoch format), integration time, UV/VIS/IR sensor gain settings, raw UV/VIS/IR sensor counts, a flicker measurement, and the computed illuminance in lux. For example, the ALS data columns are named: `time_stamp`, `integration_time`, `uvGain`, `visGain`, `irGain`, `uvValue`, `visValue`, `irValue`, `Flicker`, and `Lux`.
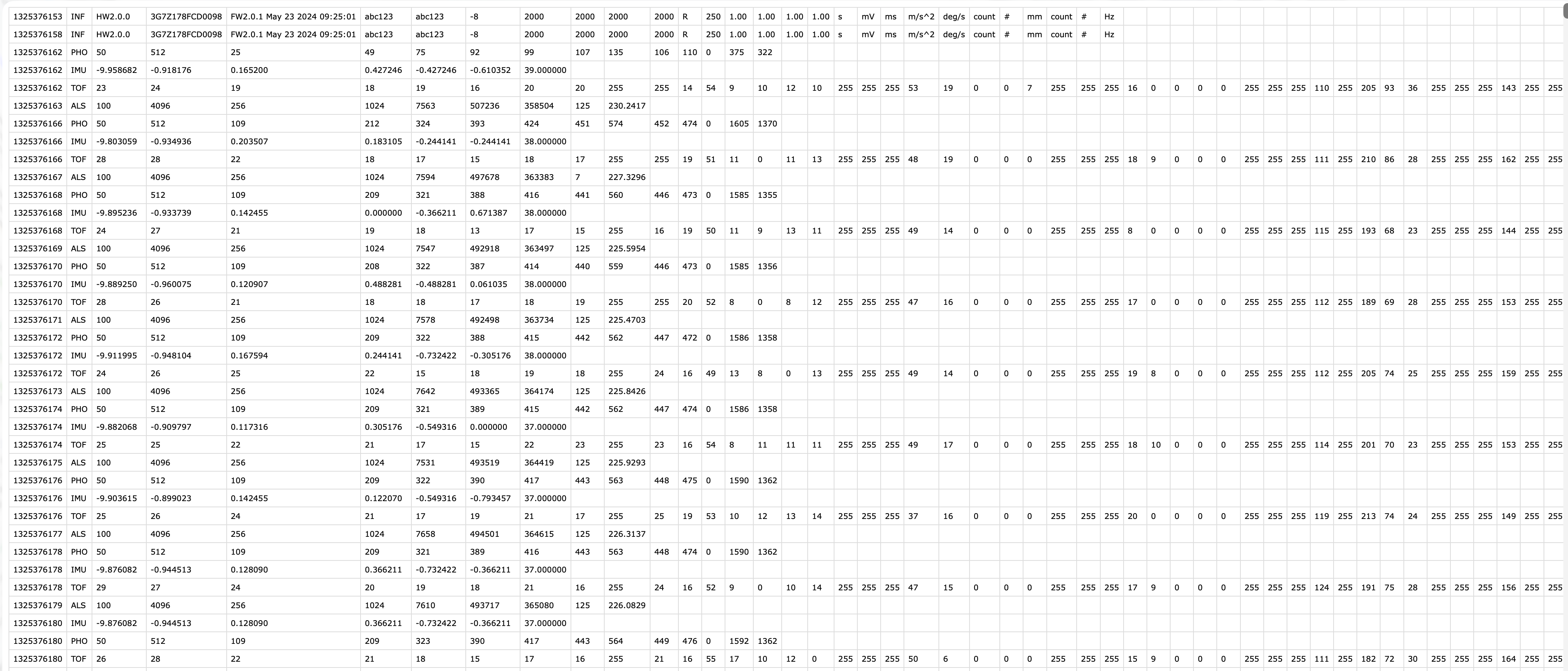{#fig-VEET_file}
For the **PHO (spectral) modality**, the columns include a timestamp, integration time, a general `Gain` factor, and nine sensor channel readings covering different wavelengths (with names like `s415, s445, ..., s680, s940`) as well as a `Dark` channel, a broadband channel `Clear`, and another broadband channel for flicker detection (`FD`). In essence, the `VEET`’s spectral sensor captures light in several wavelength bands (from \~415 nm up to 940 nm) rather than outputting a single lux value like the ambient light sensor does (*PHO*).
To import the `VEET` ambient light data, we again use the LightLogR import function, specifying the `ALS` modality. The raw VEET data in our example is provided as a zip file (`01_VEET_L.csv.zip`) containing the logged data for one week. We do the following:
```{r}
#| label: fig-VEET-overview
#| fig-cap: "Overview plot of imported VEET data"
#| fig-height: 2
#| fig-width: 6
#| filename: Import VEET Ambient Light Sensor (ALS) data
path <- "data/01_VEET_L.csv.zip"
tz <- "US/Central"
dataVEET <- import$VEET(path, tz = tz, modality = "ALS", manual.id = "VEET") #<1>
```
1. In difference to the `Clouclip` file, we simply respecify the device type with `import$VEET(...)`, but must also provide a `modality` argument.
::: callout-note
We get one warning as a single time stamp could not be parsed into a datetime - with \~300k observations, this is not an issue.
:::
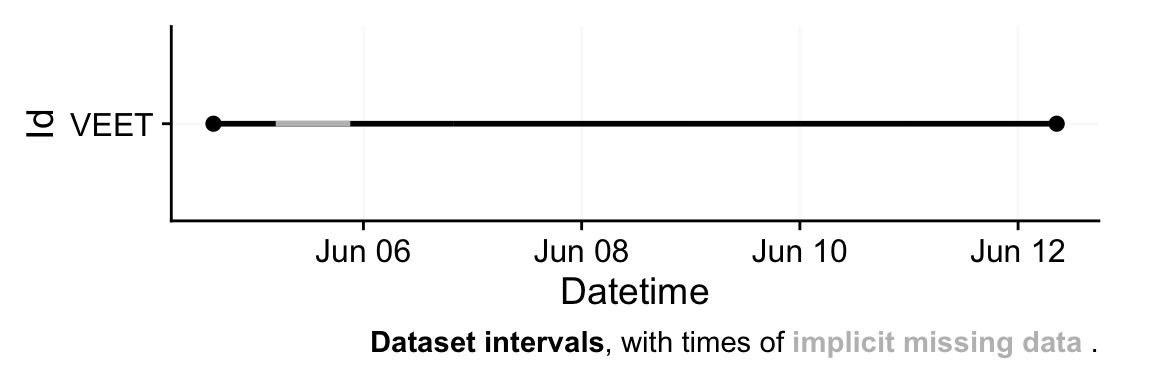
This call reads in only the lines corresponding to the `ALS` modality from the `VEET` file. The result `dataVEET` is a tibble[^3] with columns such as `Datetime` (parsed from the `time_stamp` to POSIXct in US/Central time), `Lux` (illuminance in lux), `Flicker`, and the various sensor gains/values. Columns we don't need for our analysis, like the modality code or file name, are also included but can be ignored or removed. From the import summary, we learn that the `VEET` light data, like the `Clouclip`, also exhibits irregularities and gaps. (The device nominally records every 2 seconds, but timing may drift or pause when not worn.)
[^3]: **tibble** are data.tables with tweaked behavior, ideal for a tidy analysis workflow. For more information, visit the documentation page for [tibbles](https://tibble.tidyverse.org/index.html)
```{r}
#| filename: Print the first 6 rows of the VEETs light dataset
dataVEET |> head()
```
To make the VEET light data comparable to the Clouclip’s and to simplify analysis, we choose to **aggregate the VEET illuminance data to 5-second intervals**. This slight downsampling will both reduce data volume and remove irregularities.
```{r}
#| filename: Aggregate VEET light data to 5-second intervals and mark gaps
dataVEET <- dataVEET |>
aggregate_Datetime(unit = "5 seconds") |> #<1>
gap_handler(full.days = TRUE) |> #<2>
add_Date_col(group.by = TRUE) |> #<3>
remove_partial_data(Lux, threshold.missing = "1 hour") #<4>
```
1. Resample to 5-sec bins (e.g. average Lux over 2-sec readings)
2. Fill in implicit gaps with NA rows
3. Add Date column for daily grouping
4. Remove participant days with more than one hour of missing data
First, `aggregate_Datetime(unit = "5 seconds")` combines the high-frequency 2-second observations into 5-second slots. By default, this function will average numeric columns like `Lux` over each 5-second period (and have sensible defaults for strings or categorical data). All of these *data type handlers* can be changed with the function call. The result is that `dataVEET` now has a reading every 5 seconds (or an NA if none were present in that window). Next, `gap_handler(full.days = TRUE)` inserts explicit NA entries for any 5-second timestamp that had no data within the continuous span of the recording. Then we add a `Date` column for grouping, and finally we remove days with more than 1 hour of missing data (using a more strict criterion as we did for `Clouclip`). According to the gap summary (@tbl-gaps2), this leaves six full days of `VEET` light data with good coverage, after dropping the very incomplete start/end days.
We can inspect the missing-data summary for the `VEET` illuminance data:
```{r}
#| label: tbl-gaps2
#| tbl-cap: "Summary of missing and observed data for the VEET device, light modality"
dataVEET |> gap_table(Lux, "Illuminance (lx)") |> cols_hide(contains("_n"))
```
@tbl-gaps2 shows, for each retained day, the total recorded duration and the duration of gaps. The `VEET` device, like the `Clouclip`, was not worn continuously 24 hours per day, so there are nightly gaps of wear time (when the device was likely off the participant), but not of recordings. After our preprocessing, any implicit gaps are represented as explicit missing intervals. The `VEET`’s time sampling was originally more frequent, but by aggregating to 5 s we have ensured a uniform timeline akin to the `Clouclip`’s.
At this point, the `dataVEET` object (for illuminance) is cleaned and ready for computing light exposure metrics. For example, one could calculate daily mean illuminance or the duration spent above certain light thresholds (e.g. “outdoor light exposure” defined as \>1000 lx) using this dataset. Indeed, basic summary tables in the [main tutorial](index.qmd) illustrate the highly skewed nature of light exposure data and the calculation of outdoor light metrics. We will not repeat those metric calculations here in the supplement, as our focus is on data preprocessing; however, having a cleaned, gap-marked time series is crucial for those metrics to be accurate.
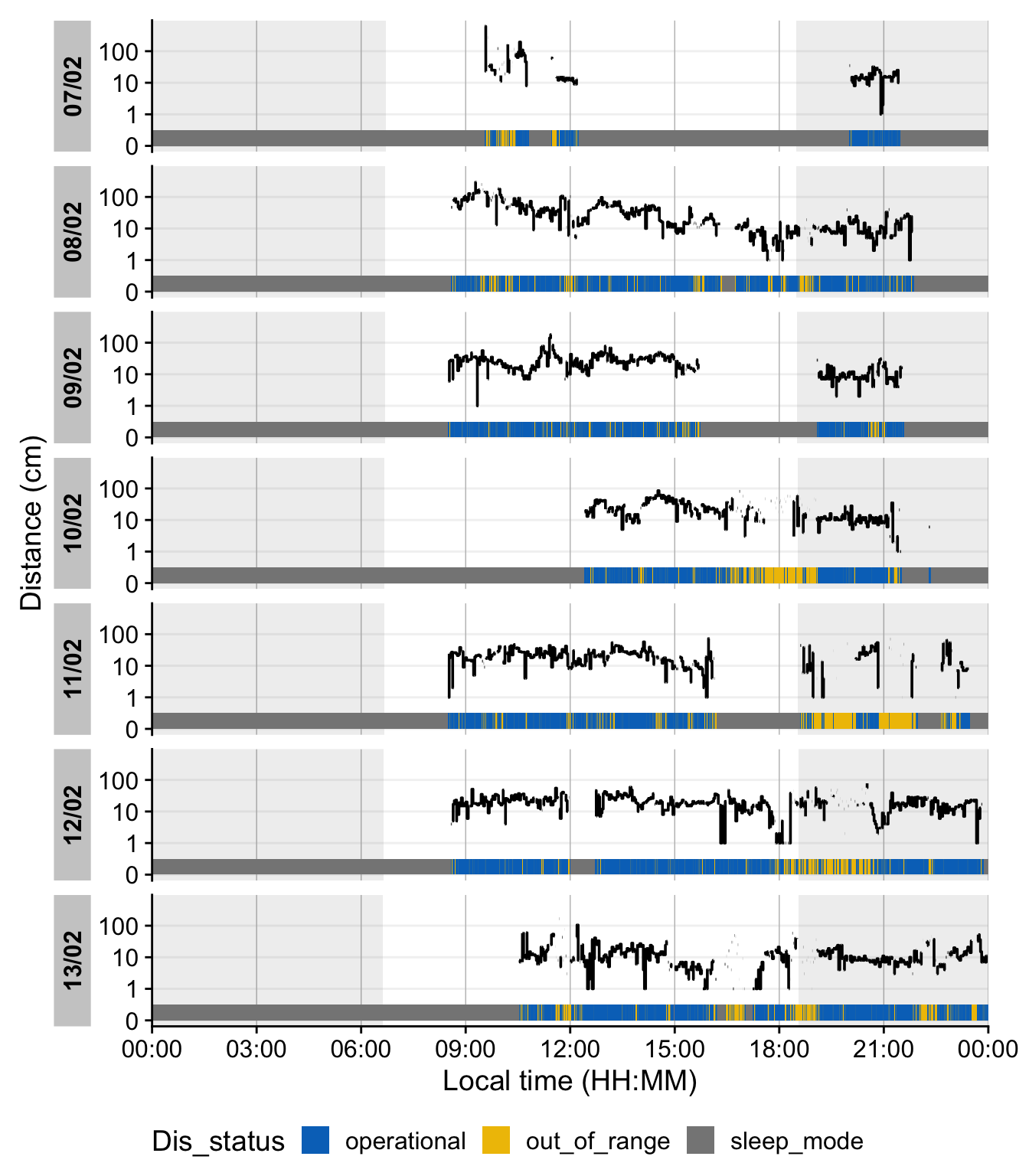
### Identifying non-wear times
Not all recorded time points of the `VEET` can be considered as `wear time`. `Non-wear` times should generally be labelled in the wearable time series, if possible. There are several ways how `Non-wear` can be classified [@Zauner2025npj]:
1. A device detects `non-wear` and does not record any measurements during non-wear times, or has a variable in the exported data to denote non-wear times. The `Clouclip` is an example here with the `sleep mode` sentinel state.
2. Record non-wear separately, e.g. with a wear-log or diary. This is easy to implement, but puts a higher burden on participants and research staff, and can be error prone: forgotten, or incorrect data entries can mis-classify wear and non-wear times. For an implementation on how to remove non-wear times based on such a log, see, e.g., this [tutorial](https://tscnlab.github.io/LightLogR_webinar/advanced_01_a_day_in_daylight-live.html). These information can also be derived from contextual information. For example, the `VEET` records charging times in a separate file `log.csv`, which can be considered as definitive non-wear times.
3. Instruct participants with a certain behavior when removing the device to ease automated detection of non-wear times in the data. These include putting a device in a black opaque bag, so that sensor readings for light are zero, or pressing an event button (if one exists). Up- and downsides are similar to the previous option, but the measures are usually harder to decipher in the data: when a buttonpress was forgotten, does that mess up the automated detection moving forward, which expects two presses per non-wear period (at beginning and at start). When there is zero lux during the day - was it in a black bag, or was this person just in a dark environment?
4. Automated detection by an algorithm. There are several possibilities to try to classify non-wear times based on the available data from a wearable. E.g., if there is an activity tracker, that can be used to determine periods of inactivity, which could indicate non-wear. If only light data is available, the standard deviation (or coefficient of variance) of light in a moving window of a few minutes can be used to determine low variance, which also indicates inactivity. Usually a histogram of values shows a spike in those periods of inactivity.
::: callout-note
#### How to handle non-wear intervals
Whether classified non-wear intervals should be removed, i.e., observations set to `NA`, or not should be a deliberate decision by the researcher. If it can be assumed that non-wear times misrepresent the measurement environment of the participant, then these observations are best set to `NA`. If, on the other hand, they might be somewhat representative, then it might be enough to label these times but still include them in analyses. Usually, this requires special instructions to the participants for non-wear. E.g., instructions for bed-time could include setting the device on the night stand facing into the room (i.e., sensors not obstructed). While this would not represent distance well, it can be considered as sufficient for ambient light measurements.
If datasets are large enough, i.e., collect data from a long enought period, `non-wear` has a diminishing effect, at least as daily metrics of light are concerned. E.g., in a monthlong study of 39 participants from Switzerland and Malaysia, [@Biller2025] found that based on a sensitivity anaylsis up to 6 hours of data could be missing **every day**, and still the daily metrics across that month would not significantly change. This assumption only holds when non-wear times are not systematic, i.e., at the same time each day.
:::
We will perform a simple variant of the third option, and look at the `VEET`'s `IMU` modality.
```{r}
#| fig-height: 2
#| fig-width: 6
#| filename: Import VEET activity (IMU) data
path <- "data/01_VEET_L.csv.zip"
tz <- "US/Central"
dataIMU <-
import$VEET(path, tz = tz, modality = "IMU", manual.id = "VEET",
remove_duplicates = TRUE, #<1>
silent = TRUE) #<2>
```
1. Some rows in the data are duplicated. These will be removed during import
2. In this instance, we skip the import summary
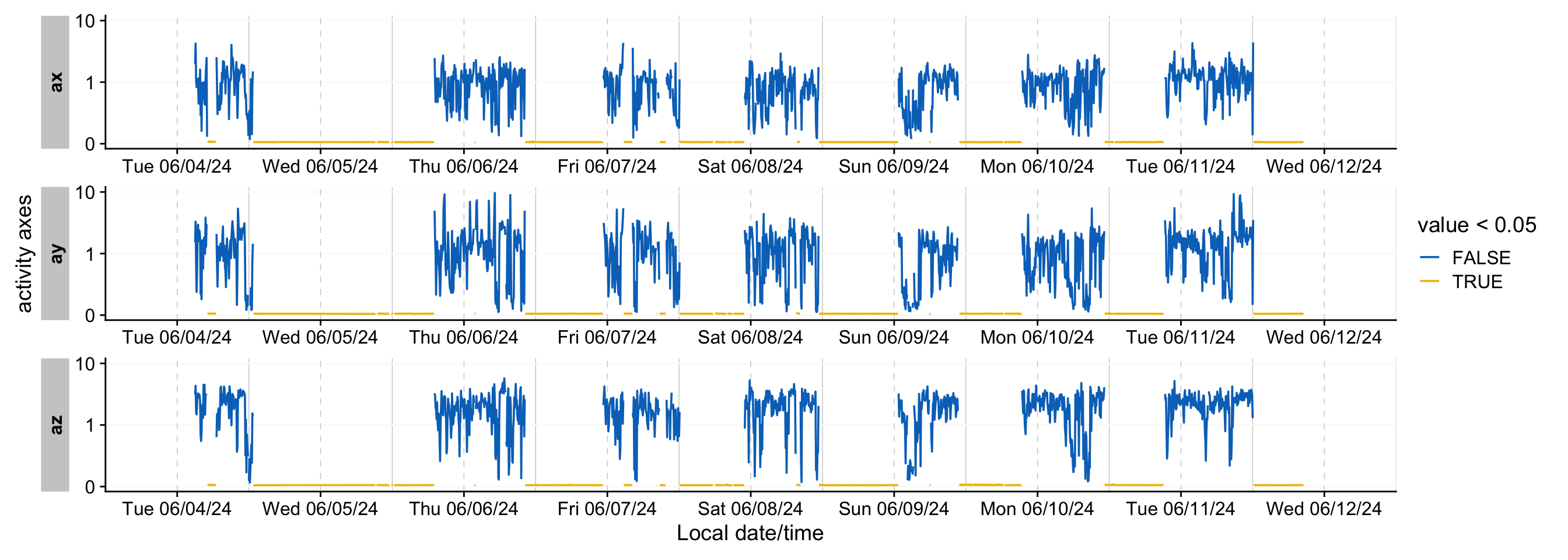
To get a quick feeling for the data, we visualize the activity variable for the x axis in @fig-IMU
```{r}
#| fig-height: 2
#| label: fig-IMU
#| fig-width: 14
#| filename: Plotting the IMU timeline
#| fig-cap: "Timeline of the activity sensor (x direction)"
dataIMU |>
gg_days(ax,
aes_col = abs(ax) < 1,
group = consecutive_id(abs(ax) < 1),
y.axis.label = "ax"
)
```
`ax` seems to vary between ±10. In general, the periods of inactivity seem to lie within a band of ±1. However, simply choosing this band does not eliminate false detections during times of high movement. Some data transformations can make these more clear:
```{r}
#| label: fig-IMU2
#| fig-width: 14
#| filename: Plotting a transformed IMU timeline
#| fig-cap: "Timeline of the activity sensor (x direction) - transformed to distinguish times of low activity"
dataIMU |>
aggregate_Datetime(
"5 mins",
numeric.handler = sd
) |>
pivot_longer(cols = c(ax, ay, az)) |>
group_by(name) |>
gg_days(value,
aes_col = value < 0.05,
group = consecutive_id(value < 0.05),
y.axis.label = "activity axes"
)
```
What @fig-IMU2 shows is that the 5-minute standard deviation of the activity channels (x, y, and z direction) allows a pretty stable distinction between periods of high and low activity, with a threshold of **0.05**. We can us this to create a wear column. As the choice of channel does not seem to matter much, we will use `ax`.
```{r}
#| filename: Calculating times of wear and non-wear
wear_data <-
dataIMU |>
aggregate_Datetime("5 mins",numeric.handler = sd) |> #<1>
mutate(wear = ax > 0.05) |> #<1>
select(Id, Datetime, wear) |> #<1>
extract_states(wear) #<2>
wear_data |> #<3>
ungroup(Id) |> #<3>
summarize_numeric(remove = c("start", "end", "epoch")) |> #<3>
gt() #<3>
wear_data <- wear_data |> select(Id, wear, start, end) #<2>
```
1. Calculation of the wear-variable
2. Extracting the start and end times of wear and non-wear
3. Summarizing wear and non-wear times in a table
We see that most of the recorded timespan is actually non-wear (including sleep), with an average wear time of 2.6 hours.
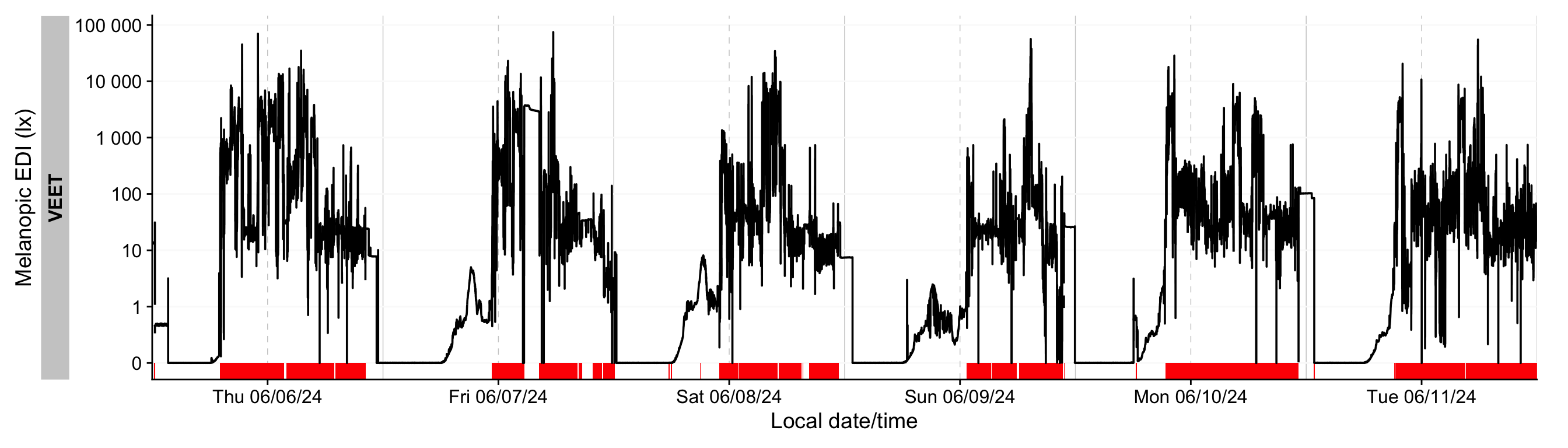
Let's add this data to the `ALS` dataset and visualize it in @fig-nonwear
```{r}
#| fig-height: 4
#| label: fig-nonwear
#| fig-width: 14
#| filename: Plotting non-wear for light
#| fig-cap: "Wear times for light data, shown as red bars"
dataVEET <-
dataVEET |>
group_by(Id) |>
add_states(wear_data)
dataVEET |>
gg_days(Lux) |>
gg_states(wear, ymax = 0, alpha = 1, fill = "red")
```
This looks sensible, e.g., when we look at noon of 7 June 2024. We can remove these observations based on the `wear` column to make our summaries more valid.
```{r}
#| filename: Removing non-wear observations from light modality
#| warning: false
dataVEET <- dataVEET |> mutate(Lux = ifelse(wear, Lux, NA)) |> group_by(Id, Date)
```
## `VEET` Data: Spectral Data Processing
### Import
In addition to broad-band illuminance and distance, the `VEET` provides **spectral sensor data** through its `PHO` modality. Unlike illuminance, the spectral data are not given as directly interpretable radiometric metrics but rather as raw sensor counts across multiple wavelength channels, which require conversion to reconstruct a spectral power distribution. In our analysis, spectral data allow us to compute metrics like the relative contribution of short-wavelength (blue) light versus long-wavelength light in the participant’s environment. Processing this spectral data involves several necessary steps.
First, we import the spectral modality from a second `VEET` file. This time we need to extract the lines marked as `PHO`. We will store the spectral dataset in a separate object `dataVEET2` so as not to overwrite the `dataVEET` illuminance data in our R session:
```{r}
#| label: fig-VEET-overview2
#| fig-cap: "Overview plot of imported VEET data"
#| fig-height: 2
#| fig-width: 6
#| filename: Import VEET Spectral Sensor (PHO) data
path <- "data/02_VEET_L.csv.zip"
dataVEET2 <- import$VEET(path, tz = tz, modality = "PHO", manual.id = "VEET")
```
```{r}
#| filename: Print the first 6 rows of the VEETs spectral dataset
dataVEET2 |> head()
```
After import, `data` contains columns for the timestamp (`Datetime`), `Gain` (the sensor gain setting), and the nine spectral sensor channels plus a clear channel. These appear as numeric columns named `s415, s445, ..., s940, Dark, Clear`. Other columns are also present but not needed for now. The spectral sensor was logging at a 2-second rate. It is informative to look at a snippet of the imported spectral data before further processing. @tbl-PHO shows three rows of `data` after import (before calibration), with some technical columns omitted for brevity:
```{r}
#| label: tbl-PHO
#| filename: Table overview of spectral sensor data
#| tbl-cap: "Overview of the spectral sensor import from the VEET device (3 observations). Each row corresponds to a 2-second timestamp (Datetime) and shows the raw sensor readings for the spectral channels (s415–s940, Dark, Clear). All values are in arbitrary sensor units (counts). Gain values and integration_time are also relevant for each interval, depending on the downstream computation."
dataVEET2 |>
slice(6000:6003) |>
select(-c(modality, file.name, time_stamp)) |>
gt() |>
fmt_number(s415:Clear)
```
### Spectral calibration
Now we proceed with **spectral calibration**. The `VEET`’s spectral sensor counts need to be converted to physical units (spectral irradiance) via a calibration matrix provided by the manufacturer. For this example, we assume we have a calibration matrix that maps all the channel readings to an estimated spectral power distribution (SPD). The LightLogR package provides a function `spectral_reconstruction()` to perform this conversion. However, before applying it, we must ensure the sensor counts are in a normalized form. This procedure is laid out by the manufacturer. In our version, we refer to the [*VEET SPD Reconstruction Guide.pdf*](https://projectveet.com/wp-content/uploads/VEET-Spectral-Power-Distribution-Reconstruction-Guide.pdf){target="_blank"}, version *06/05/2025*. Note that each manufacturer has to specify the method of count normalization (if any) and spectral reconstruction. In our raw data, each observation comes with a `Gain` setting that indicates how the sensor’s sensitivity was adjusted; we need to divide the raw counts by the gain to get normalized counts. LightLogR offers `normalize_counts()` for this purpose. We further need to scale by integration time (in milliseconds) and adjust depending on counts in the `Dark` sensor channel.
```{r}
#| filename: Normalize spectral sensor counts
count.columns <- c("s415", "s445", "s480", "s515", "s555", "s590", "s630", #<1>
"s680", "s910", "Dark", "Clear") #<1>
gain.ratios <- #<2>
tibble( #<2>
gain = c(0.5, 1, 2, 4, 8, 16, 32, 64, 128, 256, 512), #<2>
gain.ratio = #<2>
c(0.008, 0.016, 0.032, 0.065, 0.125, 0.25, 0.5, 1, 2, 3.95, 7.75) #<2>
) #<2>
#normalize data:
dataVEET2 <-
dataVEET2 |>
mutate(across(c(s415:Clear), \(x) (x - Dark)/integration_time)) |> #<3>
normalize_counts( #<4>
gain.columns = rep("Gain", 11), #<5>
count.columns = count.columns, #<6>
gain.ratios #<7>
) |>
select(-c(s415:Clear)) |> #<8>
rename_with(~ str_remove(.x, ".normalized")) #<8>
```
1. Column names of variables that need to be normalized
2. Gain ratios as specified by the manufacturer's reconstruction guide
3. Remove dark counts & scale by integration time
4. Function to normalize counts
5. All sensor channels share the gain value
6. Sensor channels to normalize (see 1.)
7. Gain ratios (see 2.)
8. Drop original raw count columns
In this call, we specified `gain.columns = rep("Gain", 11)` because we have 11 sensor columns that all use the same gain factor column (`Gain`). This step will add new columns (with a suffix, e.g. `.normalized`) for each spectral channel representing the count normalized by the gain. We then dropped the `raw` count columns and renamed the normalized ones by dropping `.normalized` from the names. After this, `dataVEET2` contains the normalized sensor readings for `s415, s445, ..., s940, Dark, Clear` for each time point time point.
Because we do not need this high a resolution, we will **aggregate it to a 5-minute interval** for computational efficiency. The assumption is that spectral composition does not need to be examined at every 2-second instant for our purposes, and 5-minute averages can capture the general trends while drastically reducing data size and downstream computational costs.
```{r}
#| filename: Aggregate spectral data to 5-minute intervals and mark gaps
dataVEET2 <- dataVEET2 |>
aggregate_Datetime(unit = "5 mins") |> #<1>
gap_handler(full.days = TRUE) |> #<2>
add_Date_col(group.by = TRUE) |> #<3>
remove_partial_data(Clear, threshold.missing = "1 hour") #<4>
```
1. Aggregate to 5-minute bins
2. Explicit NA for any gaps in between
3. Add a date identifier for grouping
4. remove days with more than one hour of data missing
We aggregate over 5-minute windows; within each 5-minute bin, multiple spectral readings (if present) are combined (averaged). We use one of the channels (here `Clear`) as the reference variable for `remove_partial_data` to drop incomplete days (the choice of channel is arbitrary as all channels share the same level of completeness).
::: callout-warning
Please note that `normalize_counts()` requires the `Gain` values according to the gain table. If we had aggregated the data before normalizing it, `Gain` values would have been averaged within each bin (5 minutes in this case). If the `Gain` did not change in that time, it is not an issue. Any mix of `Gain` values will lead to a `Gain` value that is not represented in the gain table. While outputs for `normalize_counts()` are not wrong in these cases, they will output `NA` if a `Gain` value is not found in the table. Thus we recommend to always normalize counts based on the raw dataset.
:::
### Spectral reconstruction
For spectral reconstruction, we require a calibration matrix that corresponds to the `VEET`’s sensor channels. This matrix would typically be obtained from the device manufacturer or a calibration procedure. It defines how each channel’s normalized count relates to intensity at various wavelengths. For demonstration, the calibration matrix was provided by the manufacturer and is specific to the make and model (see @fig-calibmtx). It should not be used for research purposes without confirming its accuracy with the manufacturer.
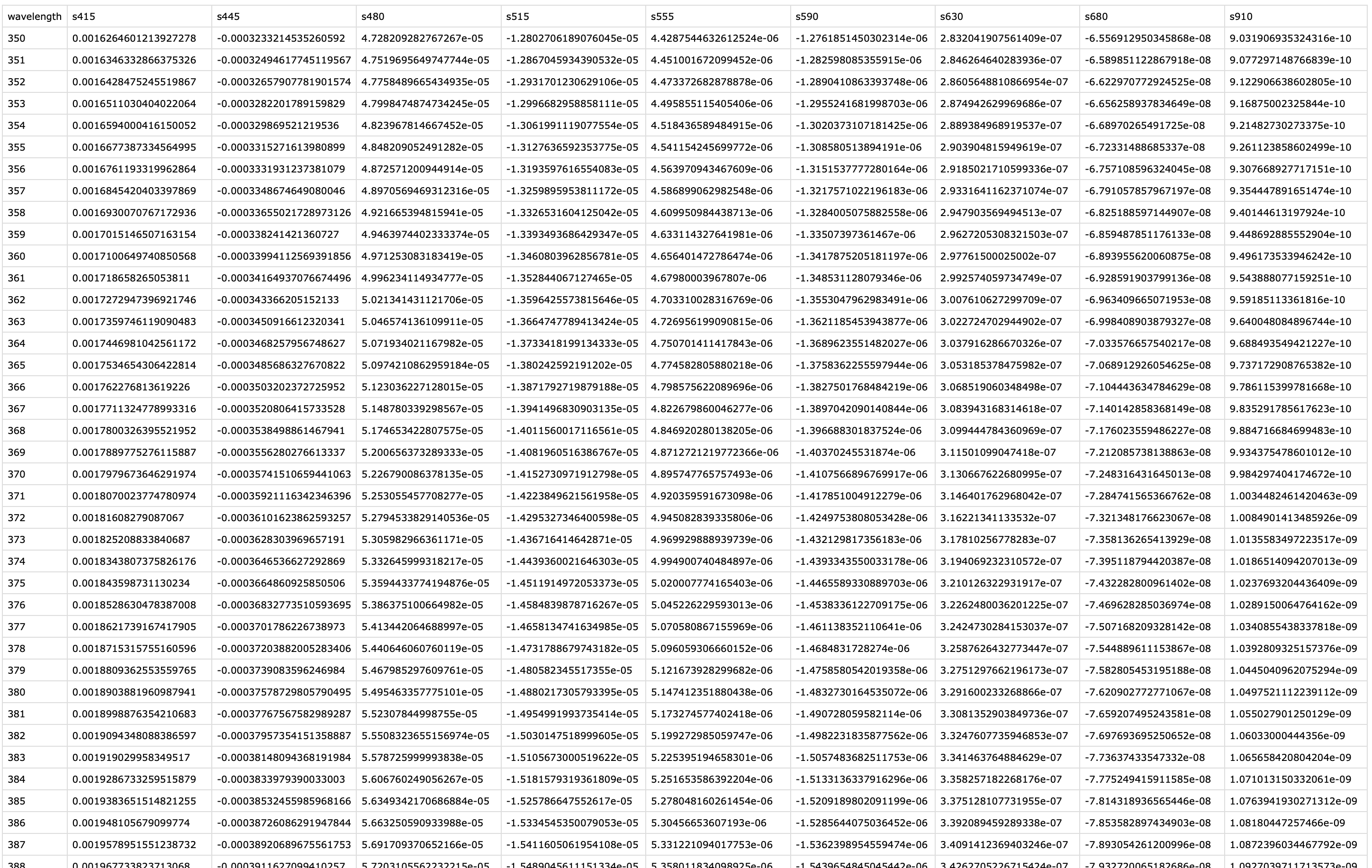{#fig-calibmtx}
```{r}
#| filename: Calibration matrica and reconstruction of spectral power distribution
calib_mtx <- # <1>
read_csv("data/VEET_calibration_matrix.csv", # <1>
show_col_types = FALSE) |> # <1>
column_to_rownames("wavelength") # <1>
dataVEET2 <-
dataVEET2 |>
mutate(
Spectrum =
spectral_reconstruction( # <2>
pick(s415:s910), # <3>
calibration_matrix = calib_mtx, #<4>
format = "long" # <5>
)
)
```
1. Import the calibration matrix and make certain `wavelength` is set a rownames
2. The function `spectral_reconstruction()` does not work on the level of the dataset, but has to be called within `mutate()`(or provided the data directly)
3. Pick the normalized sensor columns
4. Provide the calibration matrix
5. Return a long-form list column (wavelength, intensity)
Here, we use `format = "long"` so that the result for each observation is a **list-column** `Spectrum`, where each entry is a tibble[^4] containing two columns: `wavelength` and `irradiance` (one row per wavelength in the calibration matrix). In other words, each row of `dataVEET2` now holds a full reconstructed spectrum in the `Spectrum` column. The long format is convenient for further calculations and plotting. (An alternative `format = "wide"` would add each wavelength as a separate column, but that is less practical when there are many wavelengths.)
[^4]: **tibble** are data.tables with tweaked behavior, ideal for a tidy analysis workflow. For more information, visit the documentation page for [tibbles](https://tibble.tidyverse.org/index.html)
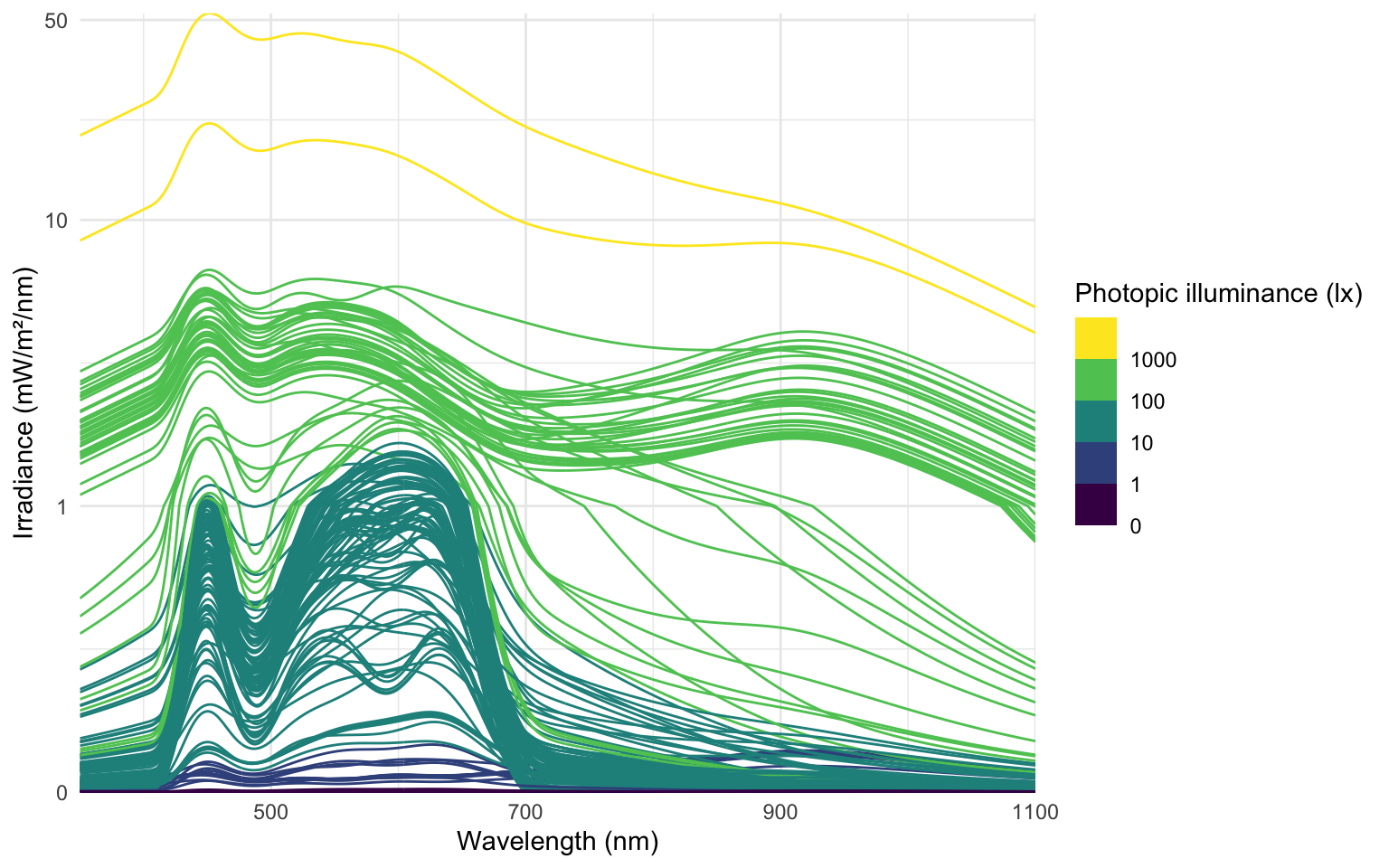
To visualize the data we will calculate the photopic illuminance based on the spectra and plot each spectrum color-scaled by their illuminance. For clarity, we reduce the data to observations within the day that has the most observations (non-`NA`).
```{r}
#| filename: Calculate photopic illuminance
data_spectra <-
dataVEET2 |>
sample_groups(order.by = sum(!is.implicit)) |> #<1>
mutate(
Illuminance = Spectrum |> #<2>
map_dbl(spectral_integration, #<3>
action.spectrum = "photopic", #<4>
general.weight = "auto") #<5>
) |>
unnest(Spectrum) #<6>
data_spectra |> select(Id, Date, Datetime, Illuminance) |> distinct()
```
1. Keep only observations for one day (with the lowest missing intervals)
2. Use the spectrum,...
3. ... call the function `spectral_integration()` for each,...
4. ... use the brightness sensitivity function,...
5. ... and apply the appropriate efficacy weight.
6. Create a long format of the data where the spectrum is unnested
The following plot visualizes the spectra:
```{r}
#| label: fig-VEET-spectra-intensity
#| fig-cap: "Overview of the reconstructed spectra, color-scaled by photopic illuminance (lx)"
#| fig-height: 5
#| fig-width: 8
#| filename: Plot spectra
data_spectra |>
ggplot(aes(x = wavelength,group = Datetime)) +
geom_line(aes(y = irradiance*1000, col = Illuminance)) +
labs(y = "Irradiance (mW/m²/nm)",
x = "Wavelength (nm)",
col = "Photopic illuminance (lx)") +
scale_color_viridis_b(breaks = c(0, 10^(0:3))) +
scale_y_continuous(trans = "symlog", breaks = c(0, 1, 10, 50)) +
coord_cartesian(ylim = c(0,NA), expand = FALSE) +
theme_minimal()
```
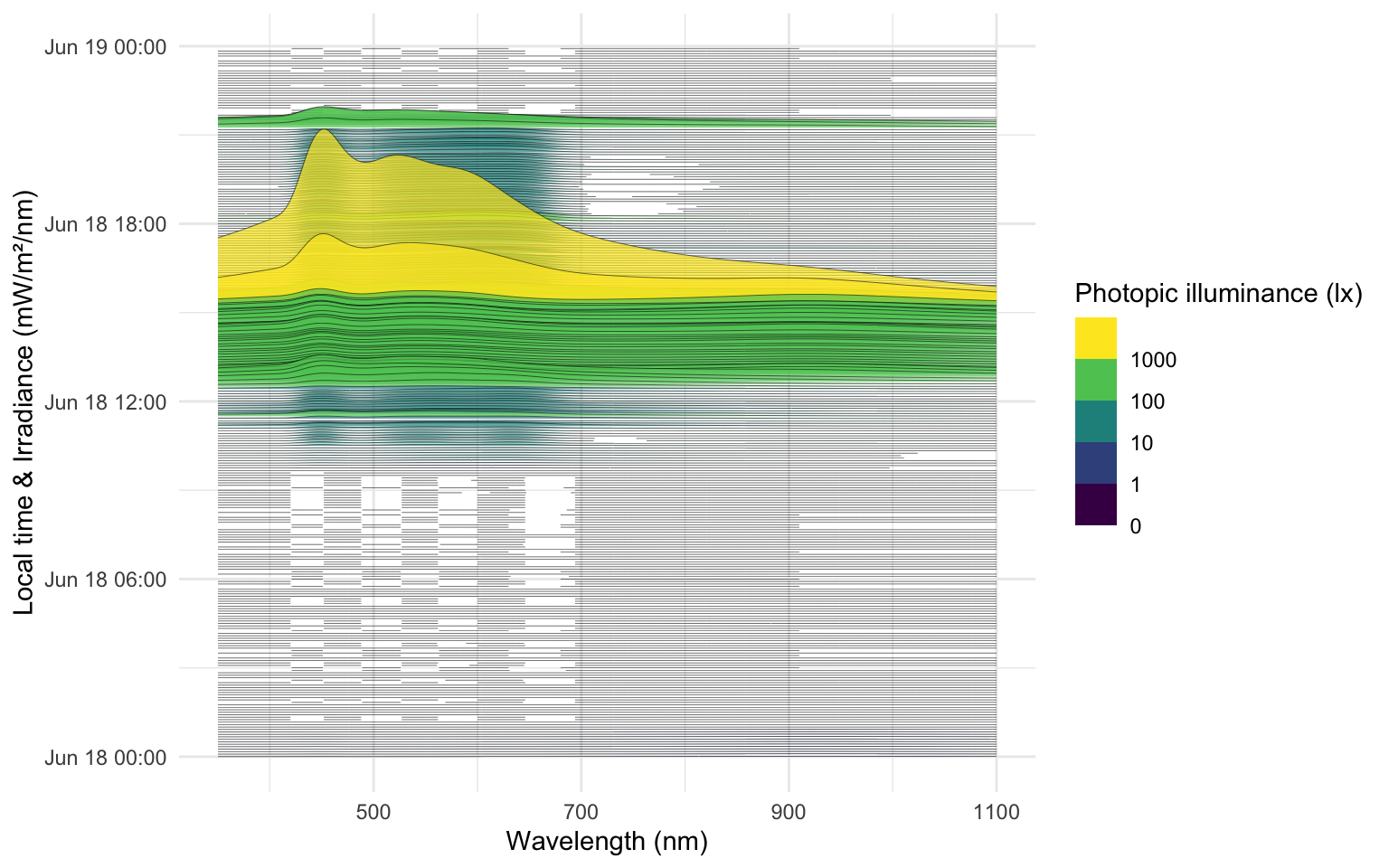
The following ridgeline plot can be used to assess **when** in the day certain spectral wavelenghts are dominant:
```{r}
#| label: fig-VEET-spectra-time
#| fig-cap: "Overview of the reconstructed spectra by time of day, color-scaled by photopic illuminance (lx)"
#| fig-height: 5
#| fig-width: 8
#| filename: Plot spectra across the time of day
data_spectra |>
ggplot(aes(x = wavelength, group = Datetime)) +
geom_ridgeline(aes(height = irradiance*1000,
y = Datetime,
fill = Illuminance),
scale = 400, lwd = 0.1, alpha = 0.7) +
labs(y = "Local time & Irradiance (mW/m²/nm)",
x = "Wavelength (nm)",
fill = "Photopic illuminance (lx)")+
scale_fill_viridis_b(breaks = c(0, 10^(0:3))) +
theme_minimal()
```
At this stage, the `dataVEET2` dataset has been processed to yield time-series of spectral power distributions. We can use these to compute biologically relevant light metrics. For instance, one possible metric is the proportion of power in short wavelengths versus long wavelengths.
In the main analysis, we defined **short-wavelength (blue light) content** as the integrated intensity in the 400–500 nm range, and **long-wavelength content** as the integrated intensity in a longer range (e.g. 600–700 nm), then computed the *short-to-long ratio* (“sl ratio”). Calculating these metrics is the first step of spectrum analysis in the [main tutorial](index.qmd#spectrum).
```
dataVEET2 |>
select(Id, Date, Datetime, Spectrum) |> # focus on ID, date, time, and spectrum
mutate(
short = Spectrum |> map_dbl(spectral_integration, wavelength.range = c(400, 500)),
long = Spectrum |> map_dbl(spectral_integration, wavelength.range = c(600, 700)),
`sl ratio` = short / long # compute short-to-long ratio
)
```
*(The cutoff of 500 nm here is hypothetical for demonstration; actual definitions might vary.)* We would then have columns `short`, `long`, and `sl_ratio` for each observation, which could be averaged per day or analyzed further. The cleaned spectral data in `dataVEET2` makes it straightforward to calculate such metrics or apply spectral weighting functions (for melatonin suppression, circadian stimulus, etc., if one has the spectral sensitivity curves).
With the `VEET` spectral preprocessing complete, we emphasize that these steps – normalizing by gain, applying calibration, and perhaps simplifying channels – are **device-specific** requirements. They ensure that the raw sensor counts are translated into meaningful physical measures (like spectral irradiance). Researchers using other spectral devices would follow a similar procedure, adjusting for their device’s particulars (some may output spectra directly, whereas others, like `VEET`, require reconstruction.
::: callout-note
Some devices may output normalized counts instead of raw counts. For example, the `ActLumus` device outputs normalized counts, while the `VEET` device records raw counts and the gain. Manufacturers will be able to speficy exact outputs for a given model and software version.
:::
## `VEET` Data: Time of flight (distance)
In this last section, the distance data of the `VEET` device will be imported, analogous to the other modalities. The `TOF` modality contains information for up to two objects in a 8x8 grid of measurements, spanning a total of about 52° vertically and 41° horizontally. Because the `VEET` device can detect up to two objects in a given grid point, and there is a confidence value assigned to every measurement, each observation contains $2*2*8*8 = 256$ measurements.
```{r}
#| label: fig-VEET-overview3
#| fig-cap: "Overview plot of imported VEET data"
#| fig-height: 2
#| fig-width: 6
#| filename: Import VEET Spectral Sensor (TOF) data
path <- "data/01_VEET_L.csv.zip"
dataVEET3 <- import$VEET(path,
tz = tz,
modality = "TOF", #<1>
manual.id = "VEET" #<2>
)
```
1. `modality` is a parameter only the `VEET` device requires. If uncertain, which devices require special parameters, have a look a the import help page (`?import`) under the `VEET` device. Setting it to `TOF` gives us the distance modality.
2. As we are only dealing with one individual here, we set a manual `Id`
```{r}
#| filename: Print the first 6 rows of the VEETs distance dataset
dataVEET3 |> head()
```
In a first step, we condition the data similarly to the other `VEET` modalities. For computational reasons of the use cases, we remove the second object and set the interval to `10 seconds`. *Note that the next step still takes considerable computation time*.
```{r}
#| label: VEET-cleaning
#| filename: Aggregate distance data to 5-second intervals and mark gaps
dataVEET3 <-
dataVEET3 |>
select(-contains(c("conf2_", "dist2_"))) |> # <1>
aggregate_Datetime(unit = "5 secs") |> # <2>
gap_handler(full.days = TRUE) |> # <3>
add_Date_col(group.by = TRUE) |>
remove_partial_data(dist1_0, threshold.missing = "1 hour")
dataVEET3 |> summary_overview(dist1_0)
```
1. Remove the second object (for computational reasons)
2. Aggregate to 10-second bins
3. Explicit NA for any gaps
In the next step, we need to transform the `wide` format of the imported dataset into a `long` format, where each row contains exactly one observation for one grid-point.
```{r}
#| label: VEET-long
#| filename: Pivot distance grid from wide to long
dataVEET3 <-
dataVEET3 |>
pivot_longer(
cols = -c(Datetime, file.name, Id, is.implicit, time_stamp, modality, Date),
names_to = c(".value", "position"),
names_pattern = "(conf1|conf2|dist1|dist2)_(\\d+)"
)
```
In a final step before we can use the data in the analysis, we need to assign `x` and `y` coordinates based on the `position` column that was created when pivoting longer. Positions are counted from 0 to 63 starting at the top right and increasing towards the left, before continuing on the right in the next row below. `y` positions thus depend on the row count, i.e., how often a row of 8 values fits into the `position` column. `x` positions consequently depend on the `position` within each 8-value row. We also add an `observation` variable that increases by `+1` every time, the `position` column hits `0`. We then center both `x` and `y` coordinates to receive meaningful values, i.e., 0° indicates the center of the overall measurement cone. Lastly, we convert both confidence columns, which are scaled from 0-255 into percentages by dividing them by `255`. Empirical data from the manufacturer points to a threshold of about `10%`, under which the respective distance data is not reliable.
```{r}
#| label: VEET-distance preparation
#| filename: Calculate grid positions of spatial distance measurements
dataVEET3 <-
dataVEET3 |>
mutate(position = as.numeric(position),
y.pos = (position %/% 8)+1, #<1>
y.pos = scale(y.pos, scale = FALSE)*52/8, #<2>
x.pos = 8 - (position %% 8), #<3>
x.pos = scale(x.pos, scale = FALSE)*41/8, #<4>
observation = cumsum(position == 0), #<5>
across(starts_with("conf"), \(x) x/255) #<6>
)
```
1. Increment the y position for every 8 steps in `position`
2. Center `y.pos` and rescale it to cover 52° across 8 steps
3. Increment the x position for every step in `position`, resetting every 8 steps
4. Center `x.pos` and rescale it to cover 41° across 8 steps
5. Increase an observation counter every time we restart with `position` at 0
6. Scale the confidence columns so that 255 = 100%
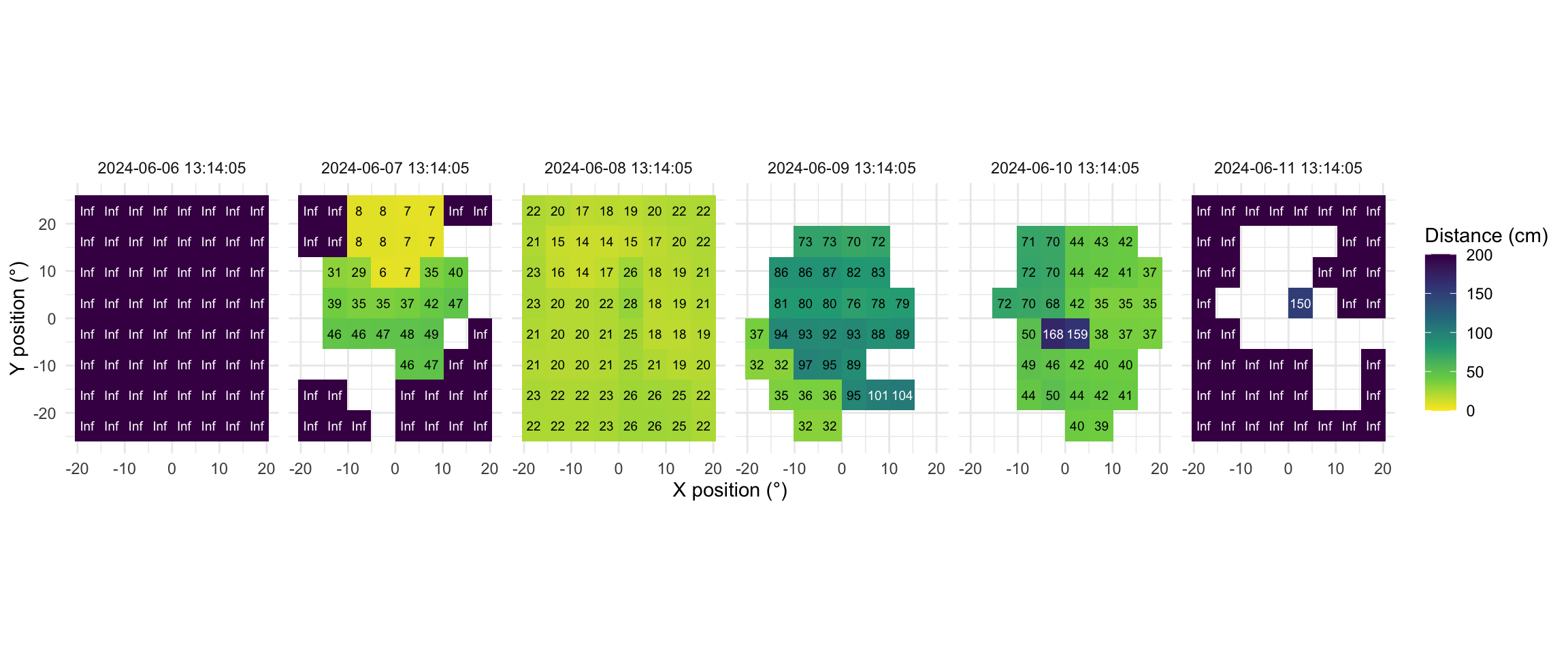
Now this dataset is ready for further analysis. We finish by visualizing the same observation time on different days. Note that we replace zero distance values with `Infinity`, as these indicate measurements outside the 5m measurement radius of the device.
```{r}
#| label: fig-VEET-distance
#| fig-cap: "Example observations of the measurement grid at 1:14 p.m. for each measurement day. Text values show distance in cm. Empty grid points show values with low confidence. Zero-distance values were replaced with infinite distance and plotted despite low confidence."
#| fig-height: 5
#| message: false
#| fig-width: 12
#| filename: Plot spatial distance grid for the same time point on each day
extras <- list( #<1>
geom_tile(), #<1>
scale_fill_viridis_c(direction = -1, limits = c(0, 200), #<1>
oob = scales::oob_squish_any), #<1>
scale_color_manual(values = c("black", "white")), #<1>
theme_minimal(), #<1>
guides(colour = "none"), #<1>
geom_text(aes(label = (dist1/10) |> round(0), colour = dist1>1000), #<1>
size = 2.5), #<1>
coord_fixed(), #<1>
labs(x = "X position (°)", y = "Y position (°)", #<1>
fill = "Distance (cm)")) #<1>
slicer <- function(x){seq(min((x-1)*64+1), max(x*64, by = 1))} #<2>
dataVEET3 |>
slice(slicer(9530)) |> #<3>
mutate(dist1 = ifelse(dist1 == 0, Inf, dist1)) |> #<4>
filter(conf1 >= 0.1 | dist1 == Inf) |> #<5>
ggplot(aes(x=x.pos, y=y.pos, fill = dist1/10))+ extras + #<6>
facet_grid(~Datetime) #<7>
```
1. Set visualization parameters
2. Allows to choose an observation
3. Choose a particular observation
4. Replace 0 distances with Infinity
5. Remove data that has less than 10% confidence
6. Plot the data
7. Show one plot per day
As we can see from the figure, different days have - at a given time - a vastly different distribution of distance data, and measurement confidence (values with confidence \< 10% are removed)
### Removing non-wear times
Same as for the `ALS` modality, we can remove times of non-wear - we can even use the same `wear_data` set for it:
```{r}
#| filename: Removing non-wear observations from distance modality
dataVEET3 <-
dataVEET3 |>
group_by(Id) |>
add_states(wear_data)
dataVEET3 <-
dataVEET3 |>
mutate(dist1 = ifelse(wear, dist1, NA)) |>
group_by(Id, Date)
```
## Saving the Cleaned Data
After executing all the above steps, we have three cleaned data frames in our R session:
- **`dataCC`** – the processed `Clouclip` dataset (5-second intervals, with distance and lux, including NA for gaps and sentinel statuses).
- **`dataVEET`** – the processed `VEET` ambient light dataset (5-second intervals, illuminance in lux, with gaps filled).
- **`dataVEET2`** – the processed `VEET` spectral dataset (5-minute intervals, each entry containing a spectrum or derived spectral metrics).
- **`dataVEET3`** – the processed `VEET` distance dataset (5-second intervals, each entry containing the distance of up to two objects in the 8x8 grid).
For convenience and future reproducibility, we will save these combined results to a single R data file. Storing all cleaned data together ensures that any analysis can reload the exact same data state without re-running the import and cleaning (which can be time-consuming for large raw files).
```{r}
#| filename: Save preprocessed files
if (!dir.exists("data/cleaned")) dir.create("data/cleaned", recursive = TRUE) #<1>
save(dataCC, dataVEET, dataVEET2, dataVEET3, file = "data/cleaned/data.RData") #<2>
```
1. Create directory for cleaned data if it doesn't exist
2. Save all cleaned datasets into one .RData file
The above code creates (if necessary) a folder `data/cleaned/` and saves a single RData file (`data.RData`) containing the three objects. To retrieve them later, one can use `<- load("data/cleaned/data.RData")`, which will return the objects into the environment. This single-file approach simplifies sharing and keeps the cleaned data together.
In summary, this supplement has walked through the full preprocessing pipeline for two example devices. We began by describing the raw data format for each device and then demonstrated how to import the data with correct time zone settings. We handled device-specific quirks like sentinel codes (for `Clouclip`) and multiple modalities with gain normalization (for `VEET`). We showed how to detect and address irregular sampling, how to explicitly mark missing data gaps to avoid analytic pitfalls, and how to reduce data granularity via rounding or aggregation when appropriate. Throughout, we used functions from LightLogR in a tidyverse workflow, aiming to make the steps clear and modular. By saving the final cleaned datasets, we set the stage for the computation of visual experience metrics such as working distance, time in bright light, spectral composition ratios, as presented in the [main tutorial](index.qmd). We hope this detailed tutorial empowers researchers to adopt similar pipelines for their own data, facilitating reproducible and accurate analyses of visual experience.
## References